In this use case, a node property is generated to assign a node to a community. You can learn about how we identify pages with similar link profiles by generating a similarity score based on links relationships to page nodes, and then running label propagation to group those similar, with the community ID written as a URL node property.
We want to be able to quickly filter or grab URLs by community ID, without knowing the community ID. We can create an index on the node property like:
CREATE INDEX ON :URL(lpa);And then run a query to grab the top 5 communities by size:
MATCH (n:URL)
WITH n, n.address as address, collect(n.lpa) as lpas
RETURN collect(address), count(address) as count, lpas
ORDER BY count DESC LIMIT 5But this actually requires some aggregation, when the whole point of graph databases are to relate data in an easy to grab way.
Convert node properties to labels with apoc
So instead we could convert those node properties to labels, which will then make them automatically indexed:
MATCH (n:URL)
call apoc.create.addLabels([ id(n) ], [ 'LPA_' + toString(n.lpa) ]) yield node
with node//optionallyremove node.lpa
return nodeBecause labels are auto-indexed, this is useful for quick filtering. But, depending on the number of communities, it could get hairy:

The benefit to labels is also the problem with – they are basically auto indexed, which means the db has to maintain the label store. So enough labels, and we’re creating an unnecessarily large index.
The other problem is getting that original data we wanted of quickly getting the top 5 communities by size.
Convert a node property into a relationship with a new node
The other thing which may be cleaner is to convert url node lpa properties to a relationship with a corresponding community node:
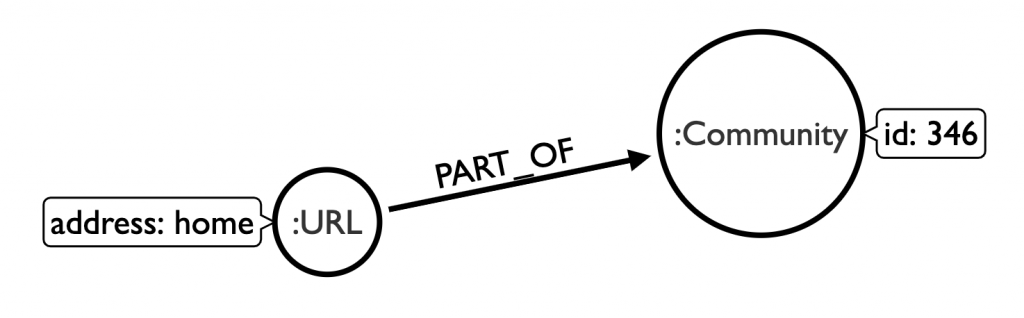
We create a constraint on the new node type so that we aren’t creating duplicate nodes with the same :Community property.
// first create a constraint so each lpa number only gets one Community nodes
CREATE CONSTRAINT ON (t:Community) ASSERT t.lpa_num IS UNIQUE;Then we map our properties out to the new Community nodes, with a MERGE
// match all url node lpa properties and merge as related to respective community node
MATCH (n:URL)
WITH n, n.lpa as lpanumber
MATCH (n:URL {lpa: lpanumber})
MERGE (c:Community {lpa: lpanumber})
MERGE (n)-[r:PART_OF]->(c)
RETURN count(c)We can change our URL caption to match our community id property and then expand some of our community nodes to make sure they match properly. Now grabbing all URLs that are part of a community will be quick and easy, and querying by community size becomes a function of
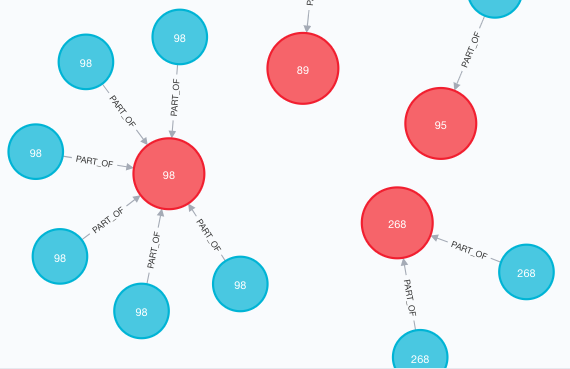
Now to run a query to grab the top 5 communities by size:
MATCH (n:Community)-[p:PART_OF]-(u:URL)
RETURN n.lpa_num, count(p) ORDER BY count(p) DESC LIMIT 5So let’s compare our first query for the top 5 largest communities (as node properties) to our last query for the same thing but as a query of related nodes:
Query node property and use collect() to sort
6083 total db hits in 3 ms
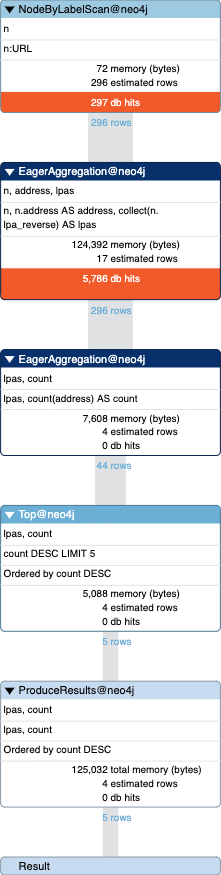
Query for related nodes (popped out from original node prop)
772 total db hits in 1 ms.

Query for labels (popped out from original node prop)
889 total db hits in 17 ms
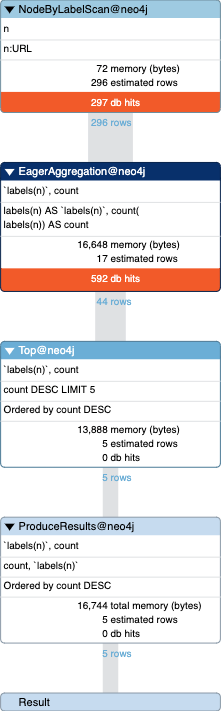
Similar query for CALL apoc.meta.stats() YIELD labels RETURN labels must check the label index? 0 db hits
It looks like popping node properties out as a related community node for each respective node makes them not only faster to query with better memory, but also easier to write and run, rather than using COLLECT() .