I am exploring how combining graph algorithms can help with more quickly analyzing a site’s structure or labeling it’s content/pages.
This is a proof of concept for using a similarity algorithm and then applying labels with another algorithm based on URLs sharing similar internal link profiles using GDS plugin with Neo4j graph database using a URL nodes and their internal links as relationships for my old site, contentaudience.com.
Understanding “similarity” in the context of link profiles
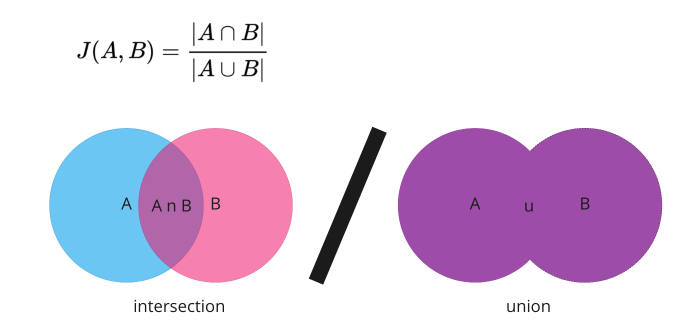
Jaccard Similarity is one of the simpler similarity algorithms to understand. I go in more detail in the above video but suffice it to say, it provides a similarity score between 0 and 1 based on overlap. That is the intersection (overlap) divided by the union (not the sum).
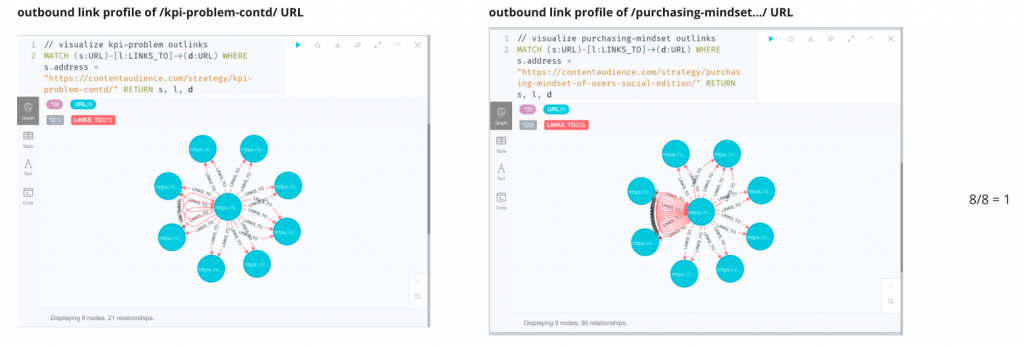
Here we see two URLs linking out to the same number of URLs, 8. So the similarity of their outbound link profile count is perfectly 1 as 8/8 = 1.
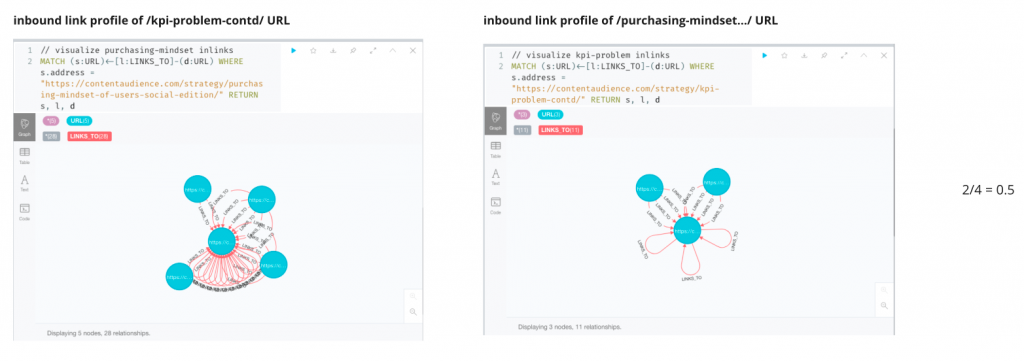
Those same URLs have different number of inbound links from other pages on the site, 4 and 2 respectively. The union is 4 and the intersection 2 so the similarity is calculated as 0.5.
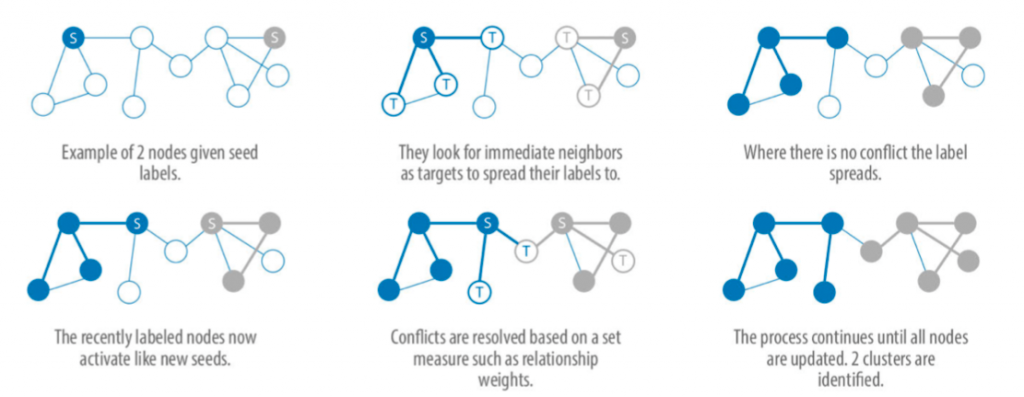
Understanding “label propagation” in the context of identifying similar link profiles of pages
Label propagation algorithms are neat. They start with random nodes in a network and propagate the same labels for all the connected nodes to the initial set nodes. Like viruses they spread until they bump up against another label, at which point conflicts get resolved based on weighted values (e.g for our purposes, higher similarity scores).
Visualizing neighborhoods of pages with similar internal link profiles
Once we run our algorithm recipe in Neo4j NEuler Graph Data Science Playground (GDS) we can visualize the clusters of pages:
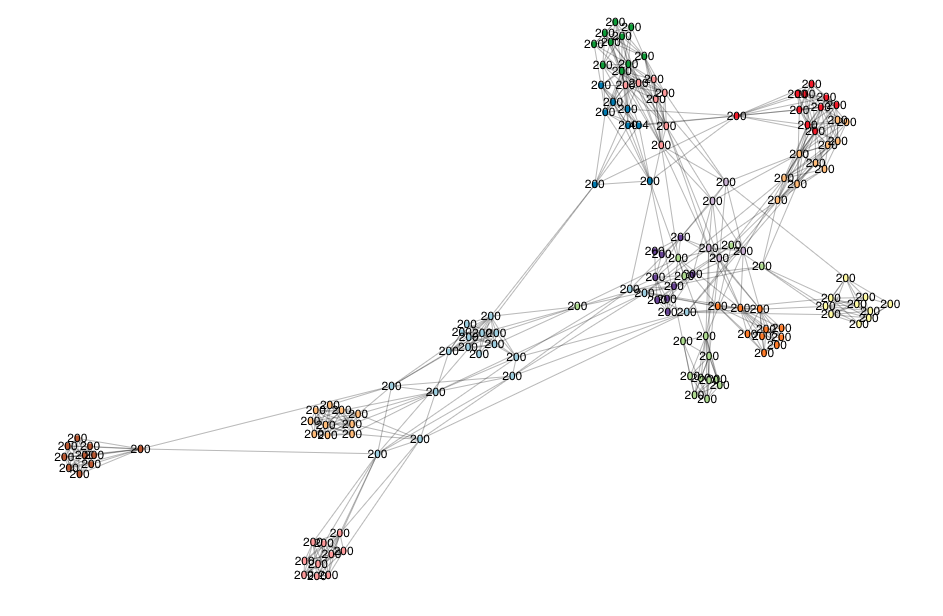
We can also zoom in and set the URL captions as the title or URL address and uncover patterns in neighborhoods we created, grouped by the number of internal inbound links in this case.
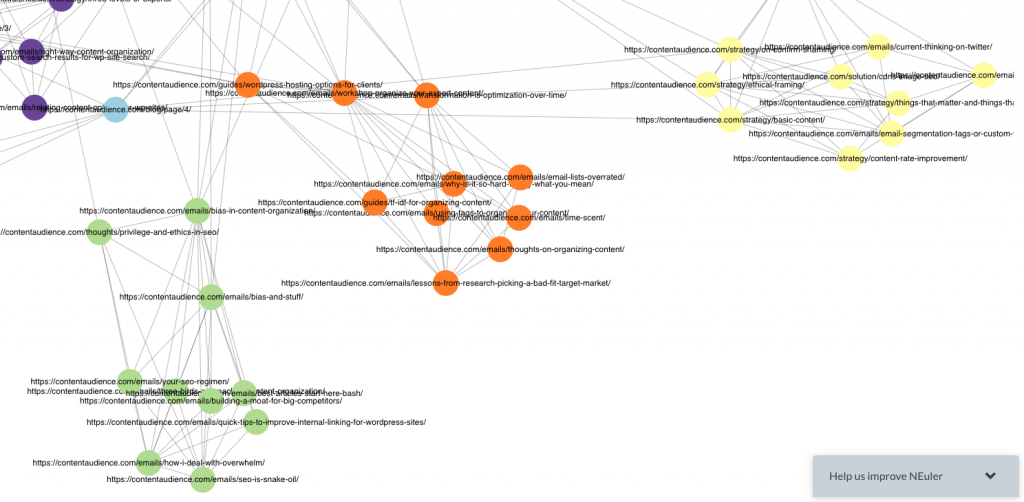
All the way off to the side, I see this “21” neighborhood.
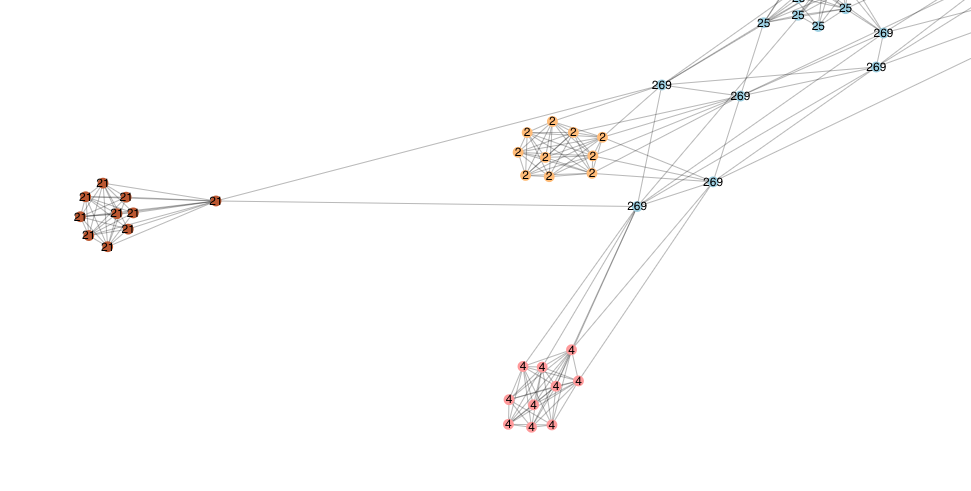
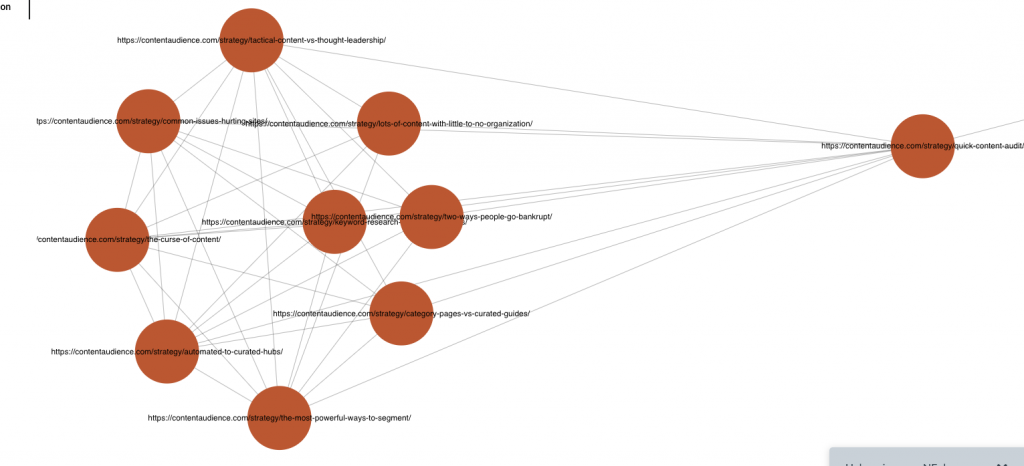
Let’s drill down into this neighborhood “21” and look at their inbound links:
MATCH (n:URL)<-[lt:LINKS_TO]-(s:URL) WHERE n.inbound_link_lpa = 21 RETURN s, lt, n LIMIT 500
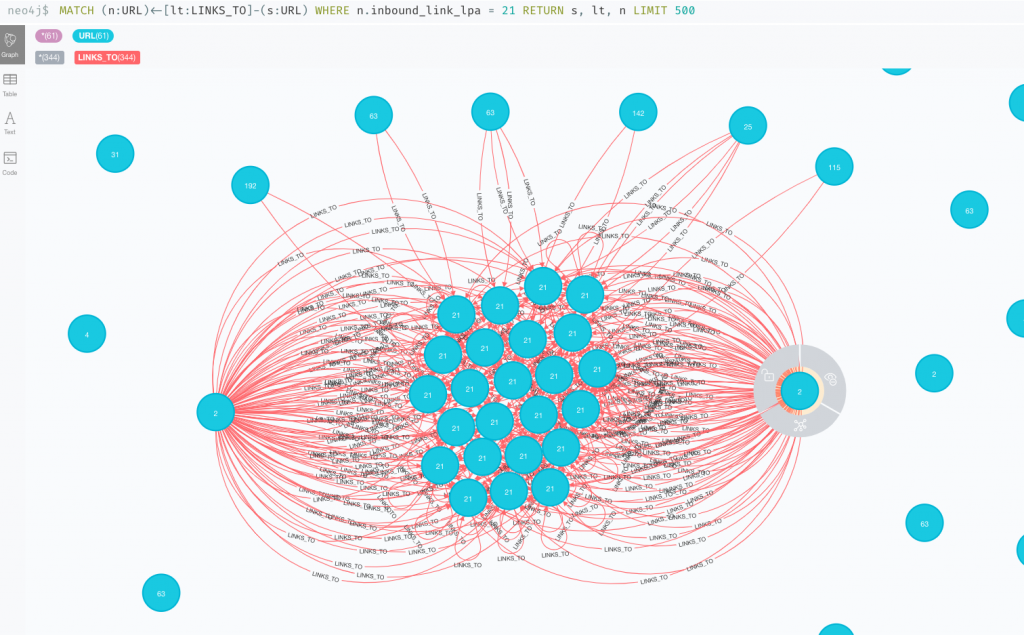
The two “2” neighborhood nodes are /author/jim-thornton/page/10/ and /blog/page/10/ And then we see some other nodes linking to a combination of these pages.
So the takeaway – we now have a list of URLs that are poorly linked to, propped up by mostly by deeply paginated archive links.