
This is the absolute path of least resistance I could come up with for running a SF crawl and getting a visual for how pages are linked in Neo4j.
- Run our crawl and export the data
- Stand up and launch Neo4j desktop or sandbox
- Put your CSVs in local where Neo is willing to open them
- Start CQL'ing
- Prep and map our rows/columns to load into our db
- Planning how to map columns/rows to nodes and relationships with labels and attributes
- Load URL relationships into your db
- Same types of nodes with directional relationships still need to get labeled differently in the context of loading those relationships in
- Load your URL nodes with attributes data from internal_html.csv columns
TL;DR
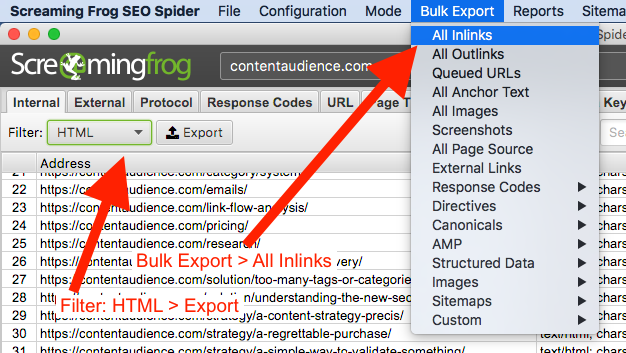
- Download Bulk Export > Inlinks and Internal HTML Export CSVs from your crawl
- Use this CQL snippet below to load the inlinks data first which creates nodes for “Addresses” and relationships for links
- Use this CQL snippet below to load your URL nodes with attributes from the internal html csv’s columns
- Boom! Run queries to analyze your site
This is a tiny tutorial so I almost feel silly thanking everyone who helped me get to this very early step on the research journey, but super grateful to Lauren OMeara, this similar tut, and Derevyanko Konstantin.
Run our crawl and export the data
First we run a standard crawl on a domain. (Make sure you have the default Screaming Frog configuration of running an internal site crawl).
It’s easier to use SF to configure any pages you want to include or exclude at point of crawl. Dealing with them later, either in a spreadsheet tool or Neo4j is not as fun or easy.
The goal is to need to do as little as possible later to get to a nice interactive graph of our site with links as relationships.
SF will give us two files:
internal_html.csv
all_inlinks.csv
Stand up and launch Neo4j desktop or sandbox
The internet knows how to do this so just ask. Basically, download the app at neo4j.com, open Neo4j Desktop, create a project, start your server (giving it a pw), and open a Neo4j browser instance to get something like this:
Put your CSVs in local where Neo is willing to open them
For me it was in:
//Users/USERNAME/Library/Application Support/Neo4j Desktop/Application/neo4jDatabases/database-ID-THING/installation-3.5.6/import/
To quickly get there in Finder on Mac, hit CMD + SHIFT + G and drop that in with the uppercase stuff replaced.
Neo4j only grabs stuff locally from this designated, auto generated folder for security purposes.
Drop the internal_html.csv and all_inlinks.csv in there.
Pro Tip: If you first load your CSV into Google Sheets, you can publish the CSV format to web and use that URL like so:
Open your Google Sheet > File > Publish to the web:
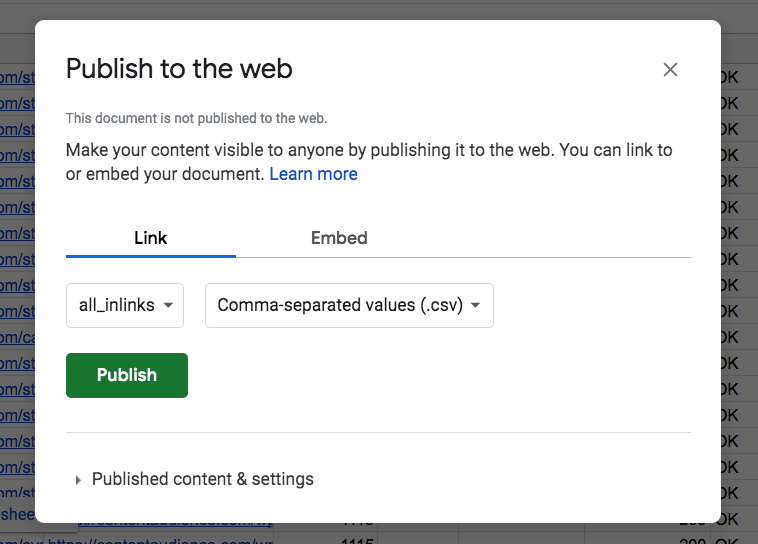
That will generate a URL on confirm that you can plug right into your LOAD CSV jawn:
LOAD CSV FROM "https://docs.google.com/spreadsheets/d/e/SOME-STRING/pub?gid=SOME-GID&single=true&output=csv" AS rowStart CQL’ing
Cypher Query Language (CQL) is like SQL which I’ve proudly managed to mostly avoid over the past 6 years. But alas, we’re here.
Making a workflow for iterating a bit easier
Some snippets to make your life easier:
// Delete everything (new node IDs don't start back at 1 though)
MATCH (n) DETACH DELETE n;For me, a good starting workflow was just:
- write a WRITE type query testing loading data in with LOAD CSV
- if it errored, try to understand the error it returned
- if it returned a suspect number of nodes, labels, or relations, then write a READ type query to see what I might have done wrong
- wipe and start over with the above snippet and then hitting CMD (CTRL) + Up Arrow key twice to get back to the query you were working on.
- read more docs and try again!
Prep and map our rows/columns to load into our db
The thing I actually had trouble wrapping my head around was how the columns fit together. I had to stretch my brain a bit.
A quick aside/recap
Graph databases are about “things” (nodes) and the “relationships” between those things, and you can include data like things about those things or things about those relationships (labels and attributes).
The CQL syntax is very cool because it makes this easy for us to represent real world stuff quickly:
CREATE (jim:Person) – [ relationship:HUSBAND_TO ] – (ann:Person)
Links are like those connections. Pages are like the people. People can have more than one wife and pages can have more than one link. They’re pretty much the same thing.
I can also be more than one thing…
(jim:Person:Marketer:CheeseLover:WifeLover:DogLover)
This is cool for the research project because the people in my target market can’t seem to say, “I’m a <one thing here>.”
Instead they say things, often in the third person like:
(:personsName:Entrepreneur:PodcastHost:Author:Speaker:CourseCreator)
Neo4j loves that. Have as many labels as you want and I can represent them with ease!
Planning how to map columns/rows to nodes and relationships with labels and attributes

Here’s the brain stretching part. I see the first column is type (AHREF, CSS, JS, IMG). But that actually refers to the destination URL. AHREF is actually more like WEBPAGE, or what we’re calling it: destination URL.
Then Size, Status Code, Status apply to our destination URL as well. The anchor and follow columns though, those are relationship attributes, or attributes of the link itself.
What about Alt Text? That one is kind of tricky. Alt Text is technically a parameter inside an image tag, typically they’re auto generated to display something on the source page, but I made it an attribute of the link relationship.
You have to make all these little decisions as you go and then you have to bend the syntax to your will. Very challenge. But fun.
Last aside: I actually started by loading my internal_html.csv addresses in first but after much head banging in merging relationships after, it became clear that if I could start with the relationship of page LINKS_TO page, I could add attributes to nodes easily later. I think that’s a good lesson: think relationships first.
Load URL relationships into your db
LOAD CSV FROM "file:///all_inlinks.csv" AS row
WITH row[0] AS Type, row[1] AS SourceURL, row[2] AS DestinationURL, row[6] AS StatusCode, row[5] AS Anchor
WHERE NOT Type CONTAINS 'All Inlinks' AND NOT Type CONTAINS 'Type'
MERGE (u:URL {name:SourceURL})
MERGE (d:URL {name:DestinationURL })
ON CREATE SET d.type = Type, d.statusCode = StatusCode
MERGE (u)-[lt:LINKS_TO ]->(d)
ON CREATE SET lt.anchor = AnchorSo the above is pretty hard earned. It’s also human readable but I’ll summarize:
The WHERE NOT line is just to skip the default extra row at the top of the CSVs given by SF by default. Otherwise we could load everything with LOAD CSV WITH HEADERS function for more ease.
The MERGE stuff – is to load data about nodes in without duplicating URL nodes given there are about 5600 links on the example site I’m using (my new site) and I had kept using CREATE statements and loading in new URL nodes for every relationship.
As an aside: isn’t that crazy? I have like 120 pages on my site but already 5000+ links. I started this site like a month ago and imported ~60 posts. I thought I had created a few hundred by hand or templating and then maybe another few hundred for the 6 navigation items, but 5k? Oy.
You probably have 50x more links than pages on your site too. All that link power just being spread so so thinly throughout our sites!
Let’s be better. I’ll be better.
Same types of nodes with directional relationships still need to get labeled differently in the context of loading those relationships in
From source URL (with a link) to destination URL (getting linked to). That’s why it’s all “MERGE” instead of “CREATE,” and using ON CREATE SET to set properties for passed vars.
You actually can’t LOAD CSV and call two columns of data the same thing (URL). I’m sure they think that’s more elegant or something, but whatever.
Load your URL nodes with attributes data from internal_html.csv columns
LOAD CSV FROM "file:///internal_html.csv" AS row WITH row[0] AS URL, row[6] AS TitleTag
WHERE NOT URL CONTAINS 'Internal - HTML' AND NOT URL CONTAINS 'Address'
MERGE (u:URL { name:URL })
ON MATCH SET u.title = TitleTagAnd boom goes the dynamite! Let’s see what we got:
MATCH (u)-[lt]->(d) WHERE d.name CONTAINS 'contentaudience' AND d.name CONTAINS 'strategy' and u.name CONTAINS 'strategy' RETURN u, lt, d LIMIT 25This is just a bloated imperfect noob way of saying, show me 25 nodes of pages on my site in the same blog category. But that’s interesting right? What daily emails turned into posts do I have that link to each other?
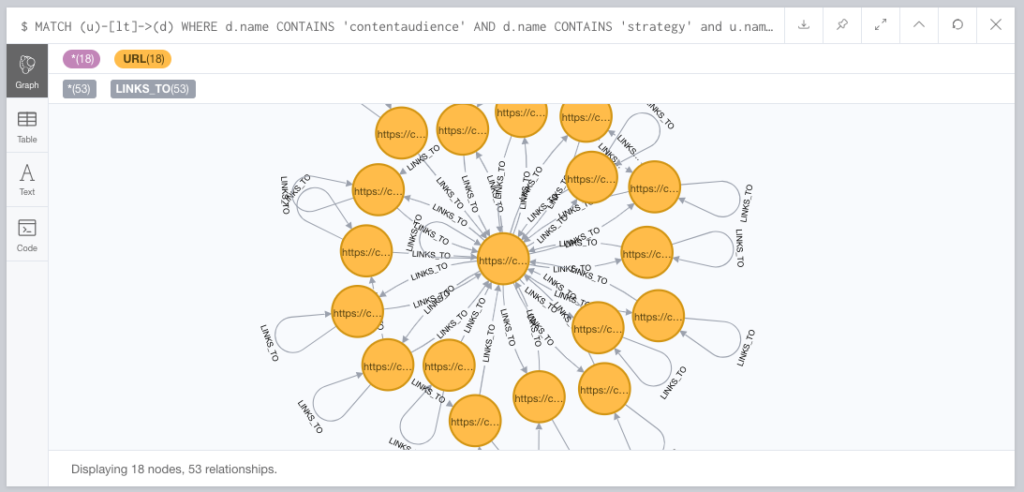
So those little self-linking loops on the outside? Yeah, they’re “skip to content” links for accessibility purposes. Most users can’t see them, they’re actually a good practice, but annoying enough that I’ll exclude them from visualizations down the line.
Actually, let’s not limit the returned nodes. Return all strategy nodes linking to each other!

See that one in the middle? That’s the /category/strategy/ page.
All my strategy posts have a “Filed under: Strategy” link to the strategy category. It’s a template thing. And it’s a WordPress archive thing for the category page and its category/page/2 type pagination to link to all the strategy posts, for indexibility, which is also fine.

That said, I would probably strip that link out and keep the text. Because a) I’m never going to rank for the word, “strategy,” and b) I shouldn’t be telling users to go look at a pile of emails pretty much ever anyway. OR maybe I really need that strategy category archive page. Hard to say without deleting it and seeing what my site would look like without it.
Which is to say, we can also just click a node and hide it to see what things would look like without it. So I demonstrate that and how even just looking at this basic data has been useful for me so far in a 6 minute (sorry) video here: