This article is in progress and incomplete.
For my first year on this journey, TF-IDF shows up a lot in NLP 101 courses, each making it sound more complex that it is and stressing it as overly simplistic and inferior to more modern (read: complicated) ways of doing keyword extraction.
And yet, for our needs of organizing content, it’s smart and elegant.
So what is TF-IDF and how do I use it?
Let’s break it down into the two parts (which then get multiplied to score a keyword for a given page/article/document.
Term Frequency
The first bit, term frequency is just what it sounds like. It refers to how frequently a term shows up in a document.
Term frequency is often categorized as a “bag of words model,” which just means getting a list of counted words/phrases in a document.
You simply get a percentage of how often words or short phrases occur in a document. If you have a term show up three times in a 500 word document, it’s scored as 3/500 = 0.006.
Alternatively, a log may be used to normalize the score. This is a pain point for me right now, I’m trying to more deeply understand the math around types of log normalization so I will update this guide at some point (hopefully).
Inverse document frequency
This one is a bit trickier, but it’s where the value comes in.
First, document frequency: what it sounds like as well – it’s a score to see how many documents have that term show up.
It seeks to determine how common a keyword is in your body of content by considering the percentage of documents that contain it. If you talk about “keyword research” in 15 of 300 documents, the document frequency is 0.05 or 0.5%.
You might think that high word and phrase counts in your library may indicate important themes or categories, and they can at medium-low scores for multi-word terms, but the most frequent words are treated as least important, as they are often “stop words,” e.g. common words you don’t care about like “the”, “be”, “a” etc..
We care about the inverse of document frequency and then use a logarithm to get a factor of relative frequencies of terms to docs with a normalized score for each term as it relates to a given document in that context.
We’re basically looking for a measure of site-wide rareness of a term. What terms are rare or distinct to a document in a collection of documents? This allows us to discern what words are important to a page relative to all the other pages on your site.
Now different libraries that will run TF-IDF have different default configs. If you remove stop words, that changes the total word counts of documents. Some measures will add 1 to the log to prevent total exclusion of non-existent terms, some use natural log, e.g. Ln(x) and some use log base 10, e.g. log(x). There are lots of variations.
For term frequency, the weight applied is plus one (+1) for every new instance of a word found. In inverse document frequency, we boost the value of a word for a specific document as a factor of how infrequently it shows up in other articles.
The TF-IDF score is normalized to a 0 to 1 scale.
For our purposes, the math boils down to lowest weights being given to words common to all pages with the highest weights given to words that appear just once on a whole site.
And that’s the gist. (End TF-IDF 101 lesson)
If you slogged through the above, you’ll be happy to know that analyzing how experts think by writing with TF-IDF is where it gets interesting.
Having the keywords extracted with TF-IDF and ignoring the weighted values of terms altogether is even useful.
For our purposes, it’s useful to consider low-ish weights, medium weights, and high weighted terms in our documents.
Here’s an example using unigrams (one word terms) and bigrams (two word terms):
First, I scrape my pages for just the article content.
Then I run it through the TF-IDF script I have for unigrams (one word terms) and bigrams (two word terms).
Here’s what the resulting .csv file looks like:
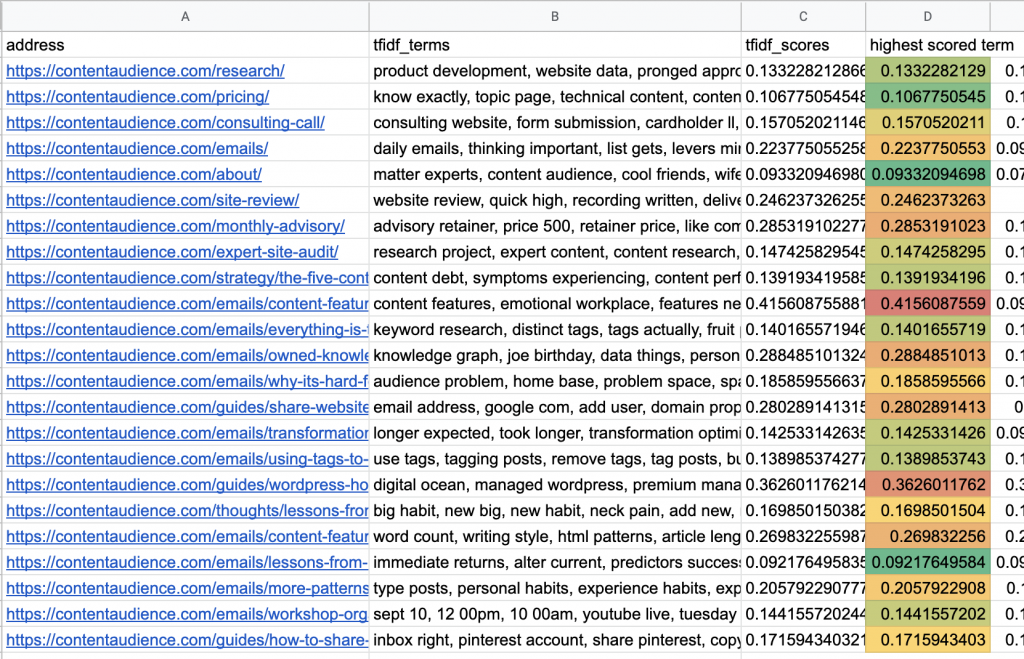
You can see my /about page’s highest scored term is tied for lowest score of the 20 or so pages shown. That makes sense. About pages are summary info, full of high level terms, generalities on terms of interest that should be present throughout the site.
The highest scored term (most rare) is “content features” and then “digital ocean,” the more medium scored terms demonstrate an interesting array.
Here’s my working heuristic for TF-IDF scoring for experts with content
Near zero to low weight single words that appear in all documents get ignored altogether. These are stop words like “is”, “the”, etc.,
Low weight phrases – not single words – that are common across the site are likely to hint at themes, common expressions, ways of phrasing things, or patterns in speech or format. So I want to review these.
Terms or phrases you use with lots of frequency can be interesting because they indicate very common patterns in how you think.
I’m reminded of my “Here’s the thing..” example, which exists in ~25% of Jonathan Stark’s emails right before his one to two sentence takeaways are provided.
Medium weight words may hint more to categories or topics, threads that are common to a line of thinking, e.g. If I talk about “content organization” in about 10% of my website’s articles, I want to know that – hence, I’ll look at medium weight terms.
A range of synonyms at the medium weight level ma also indicate larger top level taxonomy type groupings I can use as a starting point.
High weight words are the most rare. If it appears in one article, it gets the highest possible score. that is, most specific to one page. They may appear in one or two documents.
They can signal a complex treatment of a topic or idea, or long tail search intent, or bottom of funnel content, or even just be an analogy or name or book, that I referenced once.
Like anything, it has its drawbacks. I use a tables of contents a lot. The extract text function I use will then count h tag text twice on a page, ideally I would exclude them. But it’s a good quick and dirty tool.
Now that we have a bunch of extracted terms in spreadsheets, what’s next? Text analysis!
For you that may mean coming up with a list of synonyms for a given topic you see showing up consistently and then applying it as a filter:
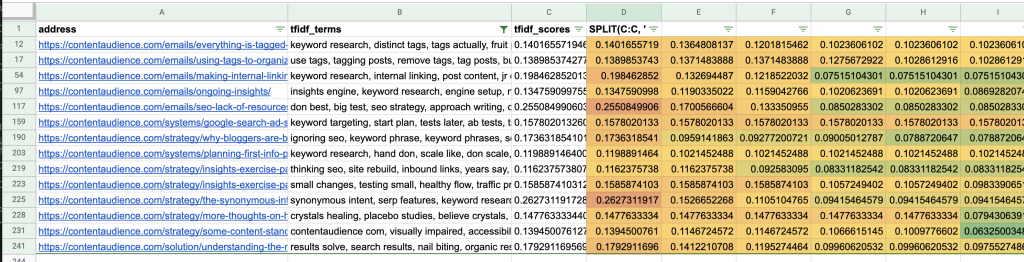
The filter REGEXMATCH(B:B,"seo|keyword|link building") get’s applied to the tfidf_terms column “C” to show all articles matching one or more of the terms “SEO”, “Keyword”, “Link Building” and now I have a good starting point for a section of my site with a curated list of articles around SEO.
Articles referencing this one