We all know what PageRank is in the context of Google / SEO, but it’s also an incredibly useful tool for internal purposes around website analysis and surfacing insights.
CheiRank is like PageRank but “using inverted direction of links” and traditionally used to “highlight very communicative nodes.” (Wiki)
This is worthwhile for SEOs as we should be interested in what pages on a website “leak” the most PageRank value in a website graph.
Okay, right. Not “PageRank,” but we should care to analyze proxies for page value, where the power pages link out to, and what improvements can be made to sculpt the flow of links throughout a site to prop up underperforming, but high potential pages.
Previously, I was using J.R. Oakes’ PageRank / CheiRank python script. But then I got rid of Moz. And never got around to re-finagling it for Ahrefs data.
And now I’m trying to do all work in Neo4j for a few reasons. One. As an SEO, I have gone all in on graphs. Not like understand how entity-relationship model and Knowledge Graph factor into Google search results, but website graphs and web graphs and applied graph algorithms and NLP for deep insights around opportunities for websites, not just technically, but in terms of content, keywords, SERP data, link data, etc.. I can be as greedy as I want with layering in more data, instead of being limited to the sad and archaic relational db model assoc.d with spreadsheets and pivot tables.
What about python / r / etc?
I’m slowing learning Python. But I’m reading Graph Powered Machine Learning by Alessandro Negro right now and learning that:
Generating an adjacency list or matrix to run calculations – what a Python script has to do – is incredibly inefficient.
I also can’t determine if a relationship exists at a glance, I can’t easily visualize if the changes I’m working on are applied correctly. And honestly, I have trouble wrapping my brain around a matrix of integers, its just less human readable.
I’ll run WordRank type processing on a corpus and it spits out keywords and scores. But I can’t drill down into the text to better understand why the algorithm thinks a given keyword or sentence is important in context. In Neo4j, I can explore the underlying structure visually and with some ease.
The other side of doing everything in Neo4j is more of a challenge to get to a point of being able to use Neo4j for Master Data Management for clients, a far way off, but why not try to streamline. I’m generally not an organized person (ironically) and have scripts and versions of scripts all over.
PageRank algo is already built into Neo4j Graph Data Science (GDS) Library plugin
The neat thing here is that I don’t have to run “PageRank” as “PageRank” I can repurpose the algo based on different weights or factors. Think using conversion data or organic traffic as initial weighted values for URLs.
So let’s figure out how to get CheiRank from PageRank.
1. Project / create a website graph that reverses link relationship direction for source and destination URLs
We reverse the link relationship direction to run PageRank on our inverted graph, returning CheiRank results.
Basically Page A LINKS TO Page B, so we “create” a graph that makes it look like Page B LINKS TO Page A, inverting the graph so that when we “run PageRank” on it, it actually returns CheiRank scores.
CALL gds.graph.create.cypher(
'chei-graph-test',
'MATCH (s:URL) RETURN id(s) AS id',
'MATCH (s:URL)-[lt:LINKS_TO]->(d:URL) RETURN id(d) AS source, id(s) AS target, type(lt) AS type'
)A tip from jonatan-neo in the Neo4j slack to improve this query was to use a native projection, which is faster:
CALL gds.graph.create(
'chei-graph-test',
'URL',
{
LINKS_TO: {
type: 'LINKS_TO',
orientation: 'REVERSE'
}
}
)2. Run (unweighted) PageRank on (the inverted website graph
CALL gds.pageRank.stream('chei-graph-test')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, score
ORDER BY score DESC, name ASCCheck the output – Did it work???
It looks good.
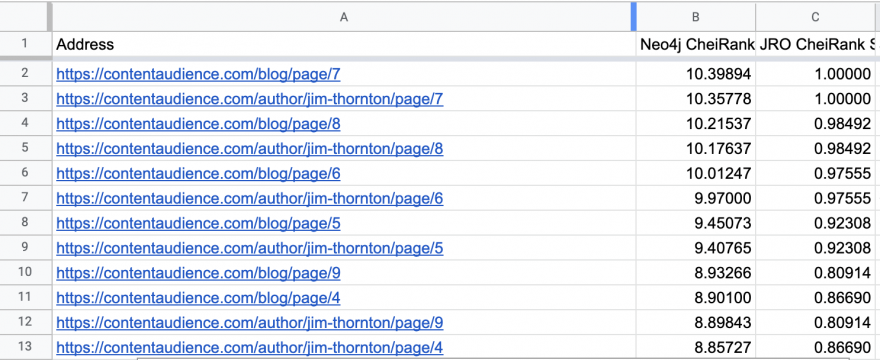
Generally, the scores are well correlated with not too bad variation:
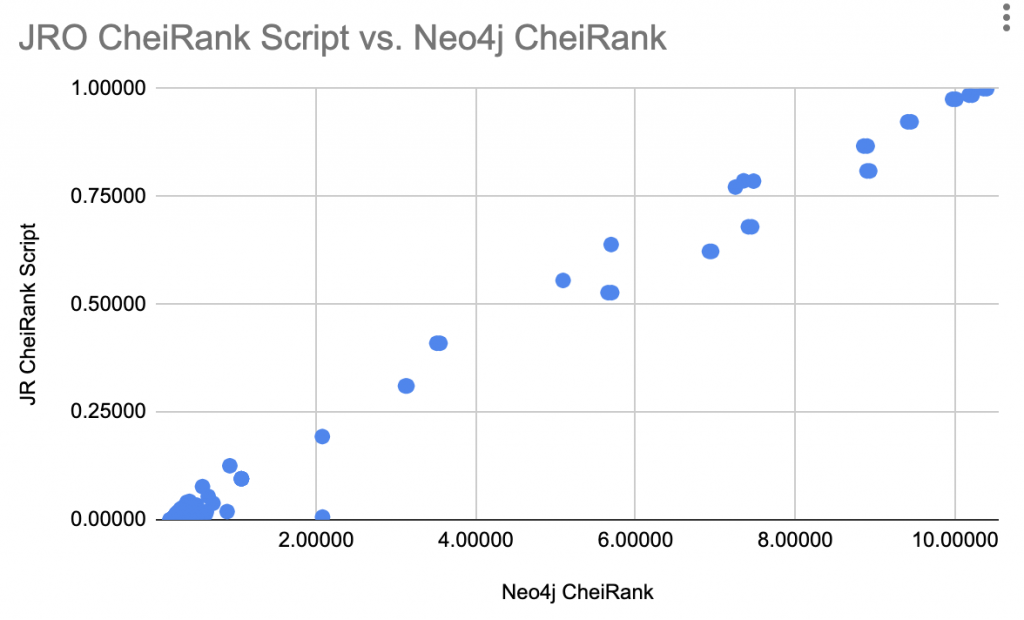
Both Oakes’ python script and inverted GDS PageRank scores generate similar scoring patterns for high CheiRank pages – but python script then normalizes scores on 0 to 1 scale.
On the high CheiRank end, we see a lot of blog, author archives, which are at their core, just lists of links so that makes sense.
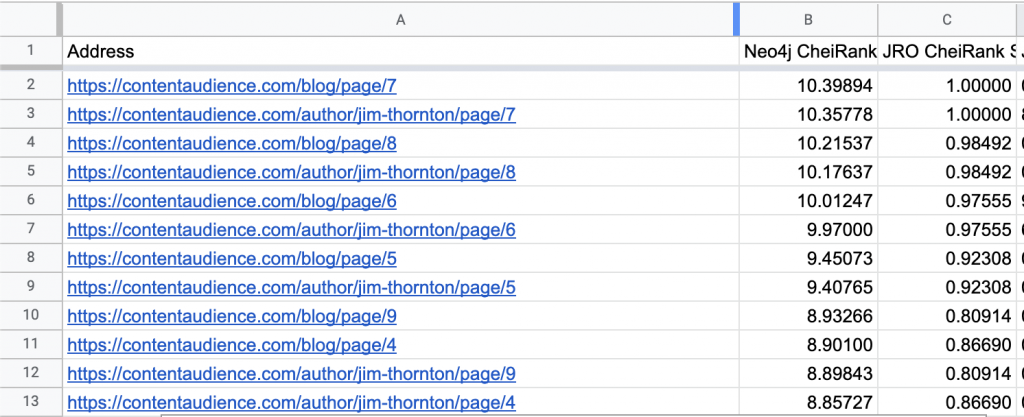
On the low end, we see a lot of emails as articles with no outbound links to other pages, also makes sense:
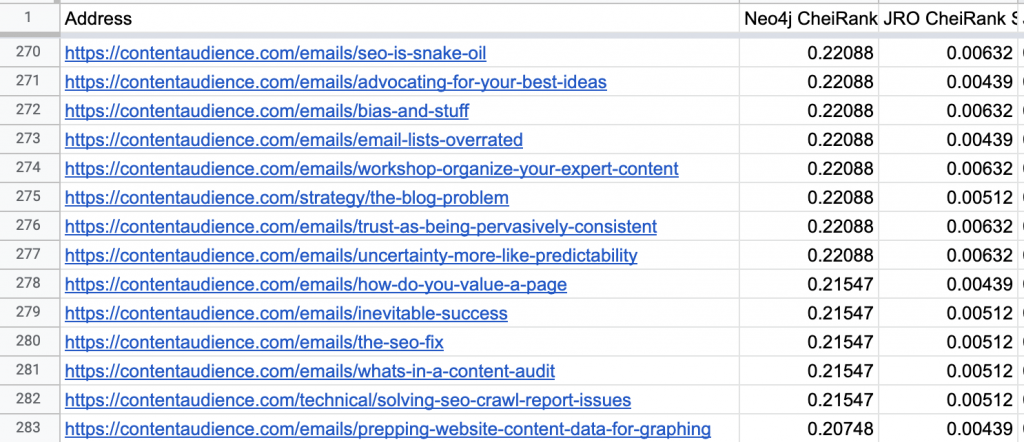
Differences in scores are likely due to
- how links are cleaned, excluded
- how redirects are counted
For example, JR Oakes script passes 301 link value to redirected URL. I count hash links as links, whereas I don’t think his does.
I am also only running CheiRank on internal website links vs python script which accounts (I think?) for all outbound links. Will have to look into that.
Actually surprising how similar they are given all those differences.
3. Enrich link data with weighted values to get better insights with CheiRank
I want to play with running PageRank and CheiRank on different weight proxies to uncover different insights. For example, it would make sense to apply Ahrefs’ Page Rating to each URL to analyze what SEOs think of as “link value flow.”
To determine where the most important “leaks” factoring in external links, I have to go outside the website – like weighting the starting value of the website’s URLs based on initial PageRank type values calculated by third party tools based on quality and quantity of inbound links from other sites to URLs.
I can add an “inbound link score” for each URL as a starting point, but then I need to split that score across the outbound links to score the link relationship.
Why?
Neo4j GDS PageRank wants a relationship property to factor in for “weight.” Not a node property. I also put my AhrefsReport data in a separate node from the URL. So I had to remap that first.
MATCH (u:URL)-[:HAS_REPORT]->(a:AhrefsReport)
SET u.ahrefs_score = a.url_rating
RETURN u.address, a.url_rating, u.ahrefs_scoreThen split the URL rating across each of the outbound links like this:
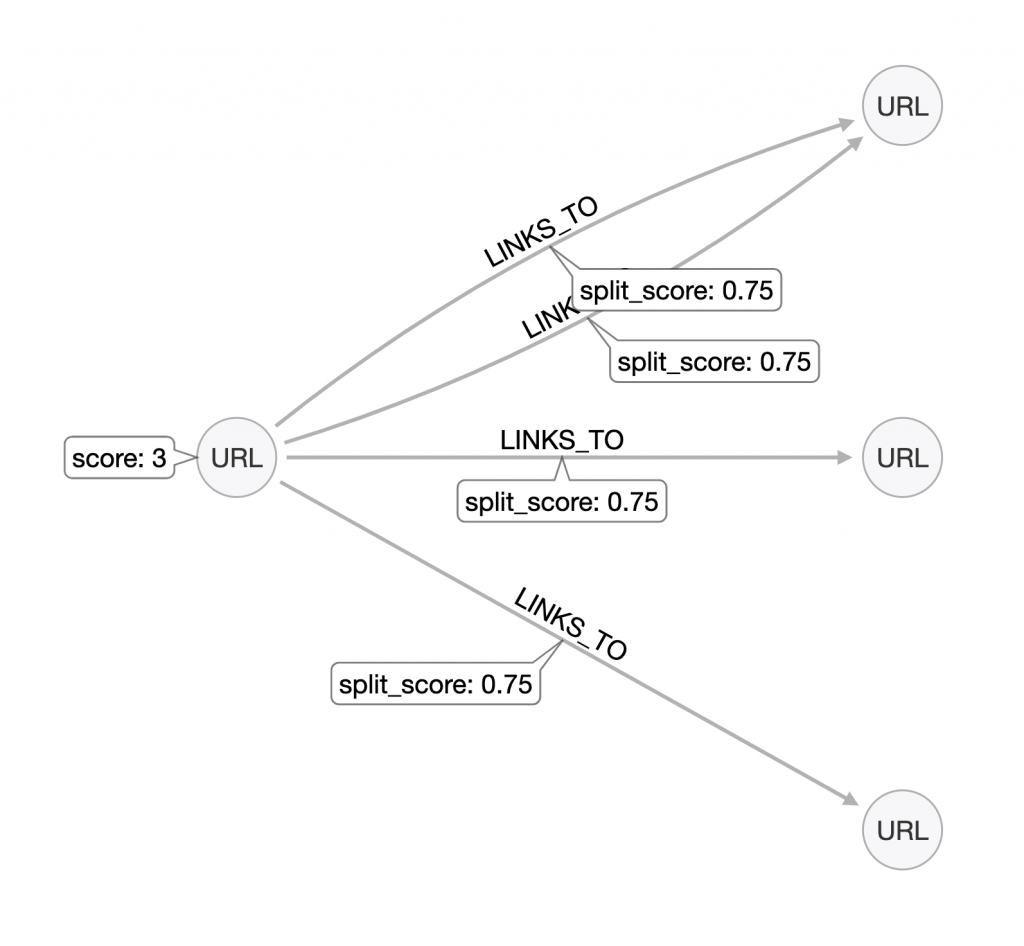
In the above model, we start with URL linking to three other URLs with a “score” of 3. The below query splits that score across the outbound links.
//split PR across links
MATCH (s:URL)
WITH s, size((s)-[:LINKS_TO]->()) as linkcount
MATCH (s)-[l:LINKS_TO]->()
SET l.split_score = toFloat( s.score / linkcount )
RETURN s.address, s.score, linkcount, l.split_score ORDER BY l.split_score DESCSimple query, but took me forever.
For 1. I didn’t understand that WITH works like RETURN and does implicit group by association. So I first had trouble passing the count of links.
And 2. for hours and hours did not realize that two integers, even with one being divided by the other would return an integer. So I kept seeing zero values and could not figure out what I was doing wrong.
Once I wrapped in a toFloat() function, it converted the integer outputs of 0s, 1s, into floating point numbers (decimals). And boom, nice split scores.
As you might have picked up – this relies on a random surfer model, splitting the link value between the links evenly.
We’ll look at proxying with reasonable surfer model for #5.
4. Run weighted Chei based on random surfer link weights
Now that we have a relationship property that we can use as our weight to calculate PageRank and CheiRank, let’s see how goes it.
CALL gds.pageRank.stream('chei-graph-test', {
maxIterations: 20,
dampingFactor: 0.85,
nodeLabels: ['URL'],
relationshipTypes: ['LINKS_TO'],
relationshipWeightProperty: 'split_score'
})
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).address AS address, score
ORDER BY score DESC, address ASCError – Relationship weight property split_score not found in graph with relationship properties: [] in all relationship types: ['LINKS_TO']
Okay it looks like the relationship property needs to be passed when creating the graph.
We need to revise the original graph projection:
CALL gds.graph.create(
'chei-graph-test2',
'URL',
{
LINKS_TO: {
type: 'LINKS_TO',
orientation: 'REVERSE',
properties: {
ahrefsplit: {
property: 'split_score'
}
}
}
}
)And now we can run our alias of “ahrefsplit” as the relationshipWeightProperty.
CALL gds.pageRank.stream('chei-graph-test2', {
maxIterations: 20,
dampingFactor: 0.85,
nodeLabels: ['URL'],
relationshipTypes: ['LINKS_TO'],
relationshipWeightProperty: 'ahrefsplit'
})
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).address AS address, score
ORDER BY score DESC, address ASCGreat success!
Our results look good at a glance. So we should write them to the database, basically gds.pageRank.stream gets replaced with gds.pageRank.write:
CALL gds.pageRank.write('chei-graph-test2', {
maxIterations: 20,
dampingFactor: 0.85,
nodeLabels: ['URL'],
relationshipTypes: ['LINKS_TO'],
relationshipWeightProperty: 'ahrefsplit',
writeProperty: 'cheiahrefs'
})
YIELD nodePropertiesWritten, ranIterationsMATCH (n)-[l:LINKS_TO]->(d)
RETURN DISTINCT n.address, n.cheiahrefs ORDER BY n.cheiahrefs DESCWe can sort DESC or ASC to just get a quick sense that what we would expect to be a high or low score is. I’m sure there is a better way to test, but good enough for me.
6. Weighted Chei based on reasonable surfer link value
Random surfer was so 90s. You can tell because old SEOs make jokes about it confusing the younger generation of SEOs.
And also because original paper used random surfer, G filed a patent for a variation based on link features in 2004, it was granted in 2010, updated again after that (covered by Bill Slawski here.)
It’s interesting that in 2004 G was already talking about “ranking documents based on user behavior and/or feature data.”
Total sidebar here.
The “or” part is interesting.
I feel like we’ve all taken that to mean feature data, link position on a page, but it’d be interesting to get some heatmap data in aggregate and come up with a model of our own where users actually click based on page layouts to inform link value. A distraction.
But we should do some weighting of link value based on how our website is linked. Websites have template footprints. WordPress for example generates a bunch of archives when you have authors, categories, tags, custom post types depending on config. This is better than nothing, but non-optimal internal linking.
Wee can pretty easily reverse query Neo4j website graph to get the most linked to pages and exclude from our split scores.
Why ignore template links?
I’m not saying ignore. I’m simply saying treat those differently. We all know where our template links are. We can update them once across a host of pages at a time. But internal links as in-article links require more nuance, and likely have significantly more value than any given template link – it provides the opportunity to internally link based on relevance, improve UX, etc.. while navigational links are used for, well, navigational intent.
How to get link position on a page?
ScreamingFrog now has a “link position” feature and we can categorize links based on their position in a website template.
From that, we can make a better weighting system for outbound links – like inline links count twice as much as footer nav links.
So wow. Cool. Let’s try!
For loading CSV data from Screaming Frog, I included link position, link type, anchor, etc., as properties on my loaded LINKS_TO relationships like so:
LOAD CSV WITH HEADERS FROM "file:///all_inlinks.csv" AS sfai WITH sfai
MATCH (u:URL {address: sfai.`Source`})
MATCH (d:URL {address: sfai.`Destination`})
CREATE (u)-[lt:LINKS_TO {
type: sfai.Type,
anchor: sfai.Anchor,
status_code: toInteger(sfai.`Status Code`),
alt_text: sfai.`Alt Text`,
follow: sfai.Follow,
link_position: sfai.`Link Position`,
link_path: sfai.`Link Path`
}]->(d)
;In a simple data model, it looks like this:

Screaming Frog gives some default link positions: head, nav, header, aside, footer, content. I tweaked these for my site. You also have to set them by priority. e.g. put .entry-content first, put any catchall sections last.
How do we decide to weight links based on position on page?
I think we tinker. We could go crazy here and look at actual click through rate data to model this. Eg. grab ~50 representative pages and look at where people go after being on those pages in GA, and then eyeball the likelihood of internal links vs nav.
Idk. Maybe we start with a proof of concept: “inline links are worth double our template links.” This should just require a bit of logic early on in our process when splitting page value across links, but will give us little hooks for those vars to tune later as needed.
Remember, our original split was randomly surfed where URL score divided by number of links was our key factor:
//split PR across links
MATCH (s:URL)
WITH s, size((s)-[:LINKS_TO]->()) as linkcount
MATCH (s)-[l:LINKS_TO]->()
SET l.split_score = toFloat( s.score / linkcount )
RETURN s.address, s.score, linkcount, l.split_score ORDER BY l.split_score DESCSo let’s create our psuedo code logic:
- If link position = content and link type = hyperlink, then 2x the value
- If link position not content and link type = hyperlink, then half the value
- (If link type not hyperlink, exclude altogether)
Ugh. It’s like the SATs.
If there are 4 links from a page with a score of 10 that are in the nav (and should get half the value), and 6 links from the same page inline in the body content (that should get double the value of the nav links), what should their scores be and how to calculate?
- get outbound link count of 4 matching inline link position = 10 / 6 * 0.333
- get outbound link count of 6 matching nav link position = 10 / 4 * 0.666
That wasn’t too hard!
First get the split of content and template links:
MATCH (s:URL)-[l:LINKS_TO]->(d:URL)
WHERE l.type = "Hyperlink" AND s.address <> d.address
WITH s, collect(CASE WHEN l.link_position <> 'Content' THEN l.anchor END) as headers, collect(CASE WHEN l.link_position = 'Content' THEN l.anchor END) as content, size(content) as articlelinkcount, size(headers) as templatelinkcountHT to Tomasi in Neo4j Slack for the help here! This returns a list of anchors and counts for all our outbound links in columns separated by in-article links and not-in-article links.
MATCH (s:URL)-[l:LINKS_TO]->(d:URL)
WHERE l.type = "Hyperlink" AND s.address <> d.address
WITH s, collect(CASE WHEN l.link_position <> 'Content' THEN l.anchor END) as headers, collect(CASE WHEN l.link_position = 'Content' THEN l.anchor END) as content, size(content) as articlelinkcount, size(headers) as templatelinkcount
//split PR across link
CASE WHEN l.link_position <> 'Content' THEN
SET l.template_split_score = toFloat( (templatelinkcount + articlelinkcount) / articlelinkcount * 2/3)
END
CASE WHEN l.link_position = 'Content' THEN
SET l.content_split_score = toFloat( (templatelinkcount + articlelinkcount) / templatelinkcount * 1/3)
END
RETURN s.address, s.score, inlinelinkcount, navlinkcount, totallinkcount, collect(l.template_split_score), collect(l.content_split_score)
ORDER BY s.score DESCI’ll replace l.template_split_score and l.content_split_score with “split_score” later, but doing this for clarity of testing.
Now that we have some initial weights on our link relationships based on Ahrefs URL ratings, we can run PageRank and Chei again and see any key differences.
Final code snippet coming soon (or not!)
Final aside – better models for reasonable surfer calculating?
I also asked JR Oakes about this on Twitter, and he had an interesting idea of using TF-IDF but instead of terms, for links. (See my pretty comprehensive explanation of TF-IDF for keyword extraction for more info on how that works.)
Edge means link relationship here. Basically if a link was found in lots of places across the site, it could be devalued based on that high frequency.
Definitely a pretty simple elegant solution.