Doing some research, it looks like the best practice is developing a preprocessing workflow around 1) whatever your goals for wrangling the data are and 2) what the raw data actually looks like.
What’s interesting about working on content at scale for entrepreneur-author-speaker types is that the challenges with cleaning their data are a) pretty generalizable (yay, leverage) and b) anything specific to the way they approach content is consistent, which means we can target those patterns.
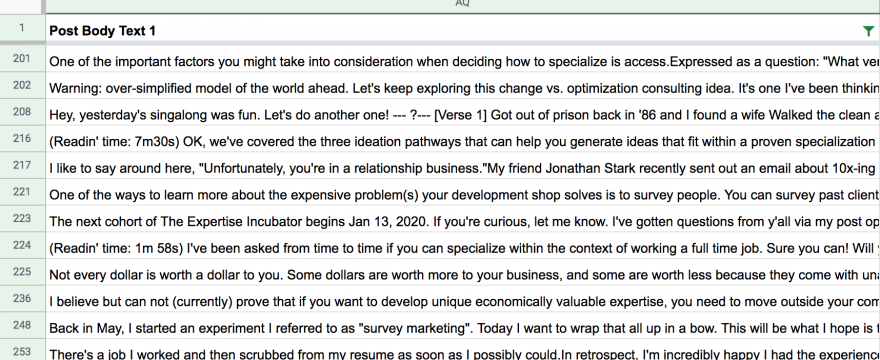
(Readin’ time: 1m 20 seconds) instances
With Philips emails turned website posts, he sometimes has a
“(Readin’ time: 3m 12s)” at the beginning of posts. But sometimes it’s a few sentences in after an announcement. And sometimes he spells out “seconds” or spaces things differently. And then rarely, he writes it like this: (Readin’ time: 16 minutes and 29 scintillating seconds).
Because it’s hand written, the pattern doesn’t seem super predictable.
To find what would be a predictable pattern we have to look closer by starting to match on certain strings like “read” or “time.” If they all start with ” (Readin’ ” and end with “)” we’re good! We can “replace” those by targeting them with regular expressions (pattern matching rules). If not, we have to account for the variance without being too greedy that we lose what we’re trying to target.
For data preprocessing, I’m still not super comfortable in Python yet. But for prescreening what needs to be pre-processed, I have some experience working in Google Sheets so starting there.
In Google Sheets I can create a filter and make a custom formula to do this, looking for all instances of parenthesis and return cells that have opening and closing ones.
=REGEXMATCH(AQ:AQ,”\(([A-Za-z]+)\)”)
Matches the string (Readin’
But Philip doesn’t only use parentheses for Readin’ time instances, it shows up all over sometimes encapsulating full sentences:
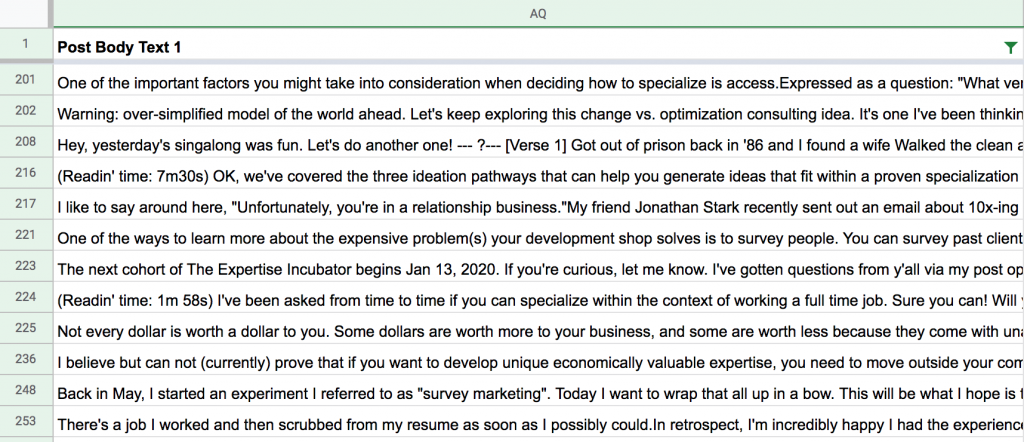
So let’s try it with starts with (Readin’
=REGEXMATCH(AQ:AQ,”\(Readin'”)
Matches the string (Readin’

This looks a lot better BUT we should also make sure that Philip doesn’t sometimes not write the parenthesis or single quotes parts:
=REGEXMATCH(AQ:AQ,”Readin”)
Matches the string Readin, Time:
=REGEXMATCH(AQ:AQ,”Time:”)
Readin casts too big a net, time: is a bit better, catches 93 instances.
Ultimately we end up with this which does a few things
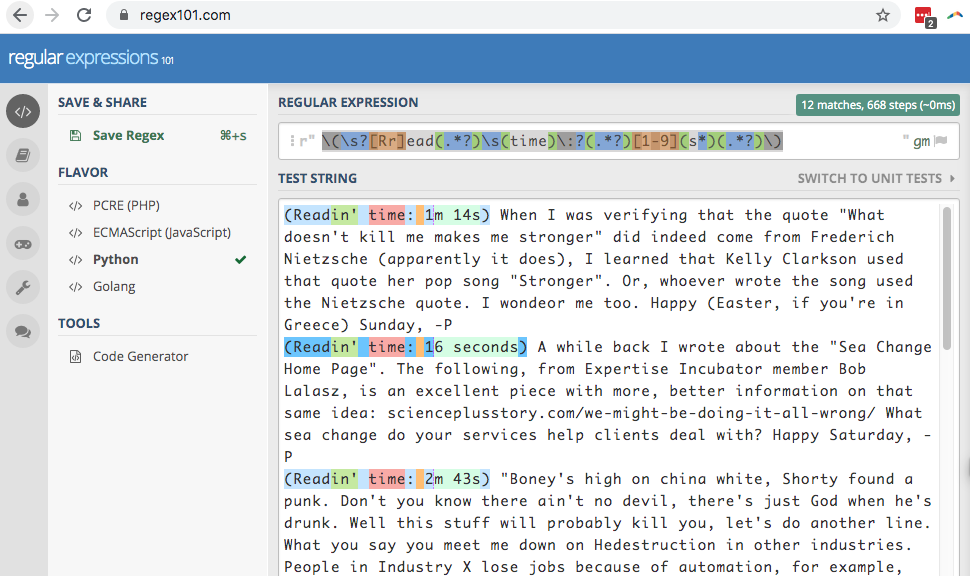
=REGEXMATCH(AQ:AQ,"\((.*?)[Rr]ead(.*?)(time)\:?(.*?)[1-9](.*?)\s(.*?)\)")It says look within parentheses for these characters in this order but allow other characters between them:
( R or r ead time : 123456789 s )
The method for “allow other characters between them are “non-greedy” so it looks between opening parenthesis and first closing parenthesis. Without them it’d look for the first instance of an opening parenthesis and match the last instance which might be later in the text sort of guaranteeing it’d find numbers and letters with keywords like read and time in unintended cases. In a preprocessing exercise, this would potentially delete large swathes of articles’ contents.
But Google Sheets relies on js based regex.
Now we have to convert that to Python friendly regex, which actually didn’t require much to be changed:
\(\s?[Rr]ead(.*?)\s(time)\:?(.*?)[1-9](s*)(.*?)\)One change I did make was replace a “match anything between “(” and “Read…” with an optional whitespace to cover “( Read” instances with space between the parenthesis and text to ensure words don’t get concatenated together, like “thanks.(Readin’ time: 21 seconds)This,” becoming “thanks.This”
You can see the testing tool I used here:
Naked link instances
Another thing somewhat unique to Philip’s writing is that he has a lot of naked text links.
There’s a personal preference (which I share) to let people clearly know what they’re clicking through to, but it often skips the “http” part that allows us to safely grab URLs instead of, say, domains, that may be intentionally referenced entities. Additionally, Philip sometimes removed the https part so that emails would be less likely to end up in spam.
But we still have to decide how wide a net we want to target. We could keep it really simple and target any string that has letters, numbers, or dashes and a period as well as any non-whitespace characters after it.
But that picks up domains.
That is, it’s different to say, “check this link out: www.hotornot.com/123/html.html” and “I hate hotornot.com as an idea.”
We don’t care about the former (for right now) but we do care about the latter.
I also had what I thought was something pretty elegant, but then I picked at it for way too long trying to reduce the number of “steps” to process under 60k times.
\(?(((((([hH]?[tT]?)|[fF]?)[tT]?[pP]?s?:?)?(\/\/)?|[A-Za-z]+|(\/\/)?)?[A-Za-z]+)\.\S+(\/|\.|#)\S+)(?!(\.com))\)?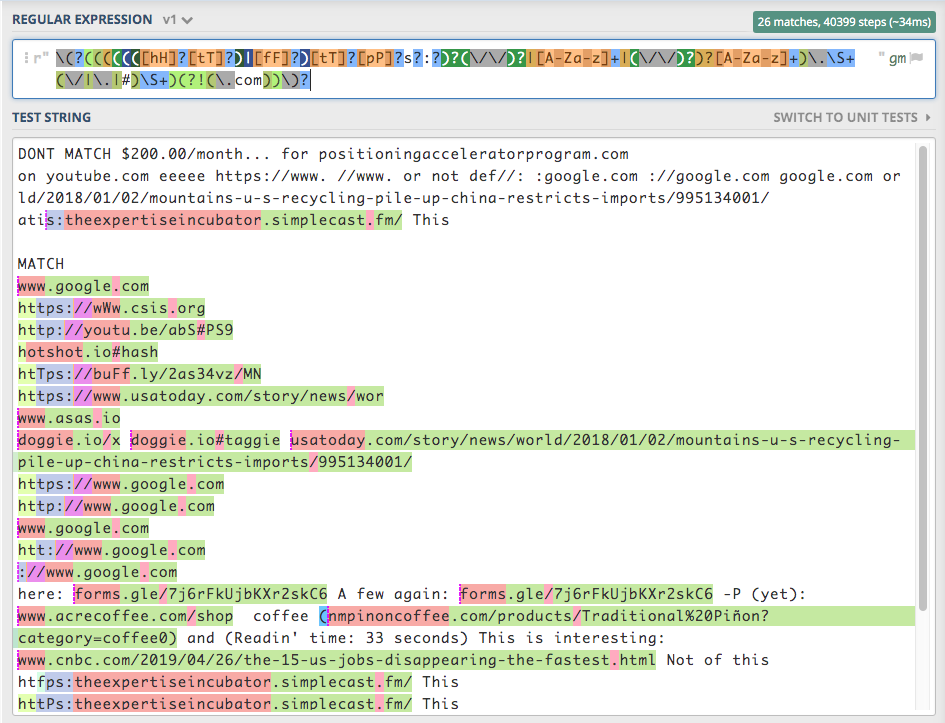
Rolling our handy regex into a preprocessing workflow
To role our regex into our Python script, we define a method. This will run string match on the regular expressions we created and replace with nothing, ” essentially removing the string, or with a space or whatever we want.
def clean(data,column):
# remove readin' time snippets
data[column] = data[column].str.replace(r"\(\s?[Rr]ead(.*?)\s(time)\:?(.*?)[1-9](s*)(.*?)\)",' ', regex=True)
# remove naked link URLs with or without http references
data[column] = data[column]/str.replace(r"\(?(((((([hH]?[tT]?)|[fF]?)[tT]?[pP]?s?:?)?(\/\/)?|[A-Za-z]+|(\/\/)?)?[A-Za-z]+)\.\S+(\/|\.|#)\S+)(?!(\.com))\)?",'', regex=True)
return data[column]
df['Post Body Text 2'] = clean(data = df, column = 'Post Body Text 1')