When I first heard about knowledge graphs (Facebook’s Open Graph and Google’s Knowledge Graph), I imagined something like a bundle of scatter plots with little avatars.
But the concepts actually pretty simple, it’s more like this:
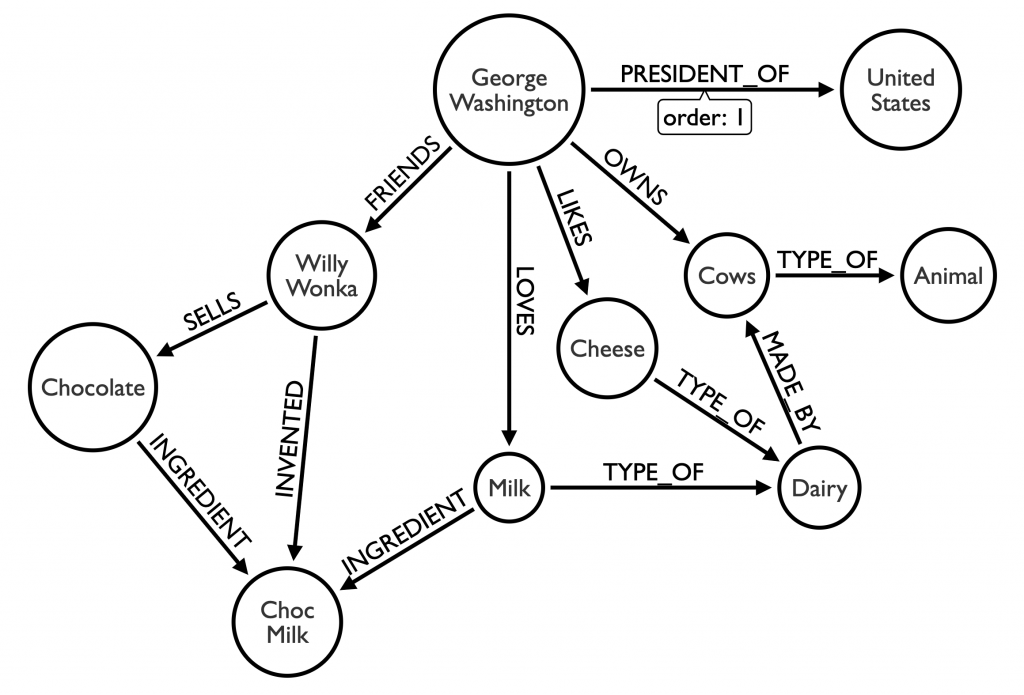
In this graph, we represent that Willy Wonka and George Washington are friends, that Willy Wonka invented chocolate milk, that given their proximity and GWs love for milk, it is likely he will try chocolate milk. We can even approximate the likelihood that he’ll love it, given he already loves the main ingredient and what we know about others who like things that are like those things.
This took 5 minutes to model and load into a graph database in a way I could then in a moment ask:
- What does GW love?
Match (:George)-[:LOVES]-(x) Return x - What did Willy Wonka invent?
Match (:Willy)-[:INVENTED]-(y) Return y - Who was the first president of the US?
Match (dude)-[prez:PRESIDENT_OF]->(:US) Where prez.order = 1 Return dude.name
If you were to compare the new way to model, load, and query that data to the old way, it’d be like comparing asking Siri to:
- going to a library
- finding some books through card catalogs
- skimming biographies and fictional histories of dairy innovation
- finding and answer, then going back and repeating
Ok so that’s just a difference in information retrieval efficiency. Big whoop.
But what if we want to estimate the odds that George Washington would try and also LOVE chocolate milk?
The old model of skimming biographies makes that impossible. I imagine whiteboarding notes out, drawing lines between things trying to piece it all together (bringing us full circle to a knowledge graph representation anyway).
The new model though? We could look for the “shortest path” between GW and chocolate milk (cheating a bit on the syntax). If GW is only two link hops away, it’s much more likely he’ll have the exposure.
MATCH (start:Person{name:'GW'}), (end:Product{name:'Chocolate Milk'})
CALL algo.shortestPath(start, end )
YIELD nodeCount RETURN nodeCountWe can also estimate likelihood with a “common neighbors” approach – typically used to predict whether two people will become friends based on the number of shared friends in common:
MATCH (gw:Person {name: 'GW'})
MATCH (cm:Product {name: 'Chocolate Milk'})
RETURN algo.linkprediction.commonNeighbors(gw, cm) AS scoreKnowledge graphs are designed to reflect a reality that respects relationships and context as being central to identity, opportunity, calamity – pretty much anything you’d want to know.
We take real world things, model them as closely to reality as possible, and then use math to summarize characteristics of how those things relate in a way that surfaces valuable insights.
Google uses its Knowledge Graph to personalize your search results.
Facebook does it to put clickbait in your newsfeed.
And I’m doing it to inform your content strategy. More later.
Aside: I also published something about types of knowledge graphs.