- Housekeeping – layer this into the current workflow
- Make sure existing GSC API import method gets rewritten to only pull data in for existing URLs
- Check and admire the initial data model
- "Split" words in each phrase nodes into related "word" nodes
- Constructing a query that gets to a worthwhile answer
- Exclude words already in the body of the articles
- Aggregate results by URL to show all missing words for articles still driving keyword impressions
- Okay, let's make this more actionable.
We can do a lot of neat stuff with Google Search Console data to improve existing rankings or further optimize pages already seeing traffic or impressions from a given series of related terms.
GSC data gets a lot more valuable as soon as we can connect it to oother data types. For example, we’re able to connect the structure of search results (SERPs) using a SERPs API to predict what efforts would most impact our CTRs as we improve our average position and navigate Google’s growing SERP features list.
I’ve also been working on a “better search volume” estimator based on impressions vs average positions data to estimate number of clicks some movement would result in given existing impressions on a, say, stable second page ranking.
Below I have come up with a neat proof of concept for how we can use really simple graph modeling to find the words in high impression keywords for a given page that aren’t actually mentioned on that page.
Again, it’s just a proof of concept, it’s not yet semantic and relies on string match of non-preprocessed data, I haven’t stemmed or pos tagged and lemmatized anything.
Skip to here for where it gets interesting
Housekeeping – layer this into the current workflow
- Create a posts directory in sitename.com-XX-XX-202X folder with that file export
- Grab all post URLs for the site
- in past SF crawl with copy / paste on sorted / filtered posts
- in post_sitemap.xml with scraper extension to spreadsheet
- in Neo with sth like
MATCH (n:URL) WHERE n.body_class STARTS WITH "post-template-default single single-post" SET n:Post RETURN n.address, n.content_text_1then export.csv renamed to internal_html.csv in /posts/ folder
- Load into fresh Neo4j db install with apoc, gds library plugins and settings updated with
dbms.directories.import=/Users/jamesmthornton/Desktop/sitename.com-XX-XX-202X CREATE CONSTRAINT ON (u:URL) ASSERT u.address IS UNIQUEand 3. internal_html CQL- edit gscapi import script – pull MERGE url out of foreach and change the MATCH so we aren’t importing unnec. url data from rest of site
Make sure existing GSC API import method gets rewritten to only pull data in for existing URLs
// 7.3 gscapi total
LOAD CSV WITH HEADERS FROM "file:///gsc-api.csv" AS gscapi WITH gscapi WHERE gscapi.`page` IS NOT NULL
FOREACH (ignoreMe in CASE WHEN COALESCE(gscapi.`page`, "") <> "" THEN [1] ELSE [] END |
MERGE (u:URL {address: gscapi.`page`}) ...
MERGE (q:Term { name: gscapi.`query`})becomes
// 7.3 gscapi total
LOAD CSV WITH HEADERS FROM "file:///gsc-api.csv" AS gscapi WITH gscapi WHERE gscapi.`page` IS NOT NULL
MATCH (u:URL {address: gscapi.`page`})
FOREACH (ignoreMe in CASE WHEN COALESCE(gscapi.`page`, "") <> "" THEN [1] ELSE [] END |
// we moved this! MERGE and made it a MATCH above
MERGE (q:Term { name: gscapi.`query`}) // should be name? was Data quality check looks good, eg.MATCH (n:Term) WHERE NOT n.name CONTAINS " " RETURN n.name LIMIT 25
But lots of word variations between treated as distinct:

We could fix this later with quick stemming on GSC data and our body content for better pattern matching, or use a part of speech API and lemmatization the same way. A quick online lemmatizer
- overcommunicate > overcommunicate
- over-communication > overcommunication
- overcommunicating > overcommunicate
investigate layering in semantic connections (synonyms) on demand
what else?
Check and admire the initial data model
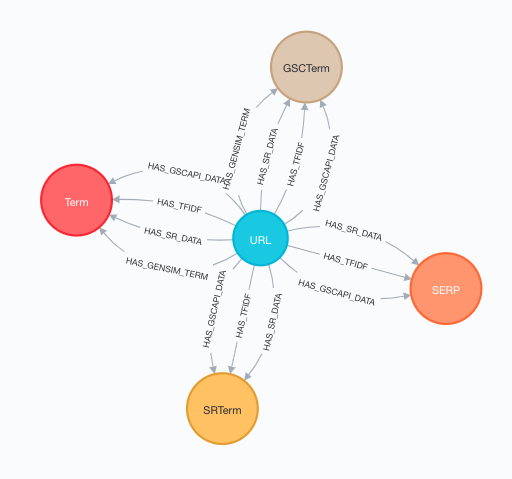
Right now the SEMRush and Google Search Console keywords are longer, typically 3 words or longer, while the extracted keywords using Word2Vec or TF-IDF are 1 to 2 words.
MATCH (n:Term)-[hw]-(w:Word)
WHERE n.name = "dialogue conversation between manager and employee"
RETURN n, w, hw
Forgot this part but should create a constraint on our word nodes, CREATE CONSTRAINT ON (w:Word) ASSERT w.name IS UNIQUE
Now let’s “split” the words in each term node out into their own “word” nodes.
MATCH (n:Term)-[hw]-(w:Word)
WHERE n.name = "dialogue conversation between manager and employee"
WITH n, n.name as phrase
WITH n, phrase, split(tolower( phrase ), " ") AS words
UNWIND range(0, size( words )-2) AS i
MERGE (w:Word {name: words[i]})
MERGE (n)-[r:HAS_WORD]->(w)
RETURN count(w)
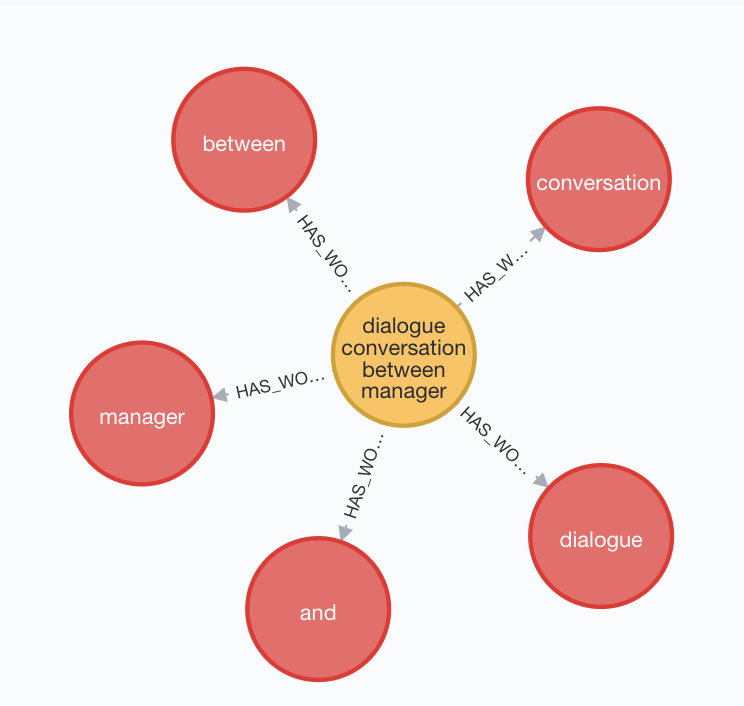
Cool! Let’s do it for all of them now. Checking the query plan with EXPLAIN returns:
140k rows affected, sounds about right.
“Split” words in each phrase nodes into related “word” nodes
MATCH (n:Term)
WITH n, n.name as phrase
WITH n, phrase, split(tolower( phrase ), " ") AS words
UNWIND range(0, size( words )-2) AS i
MERGE (w:Word {name: words[i]})
MERGE (n)-[r:HAS_WORD]->(w)
RETURN count(w)Success? Let’s check the word “boss” and its existing related search engine phrases.
MATCH (n:Term)-[hw]-(w:Word)
WHERE w.name = "boss"
RETURN n, w, hw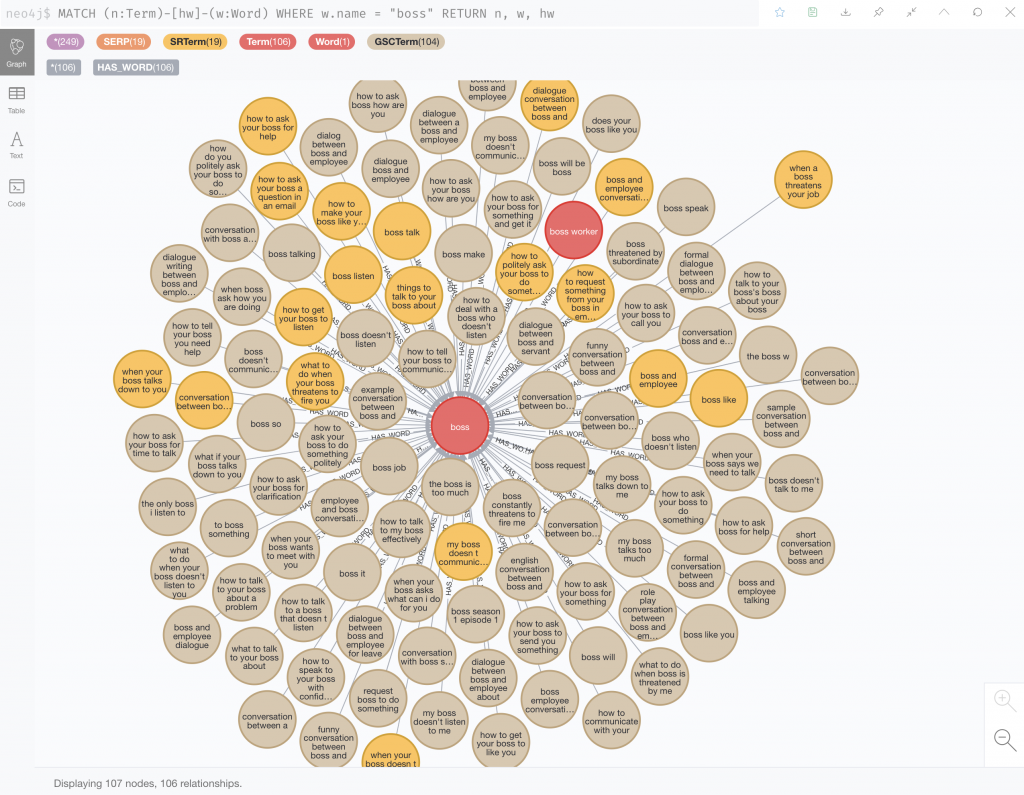
Let’s make this useful – show me Google rankings about bosses and employees.
MATCH p=(w1:Word)--(n:Term)--(w2:Word)
WHERE w1.name =~ "boss|manager" AND w2.name =~ "employee|worker"
RETURN p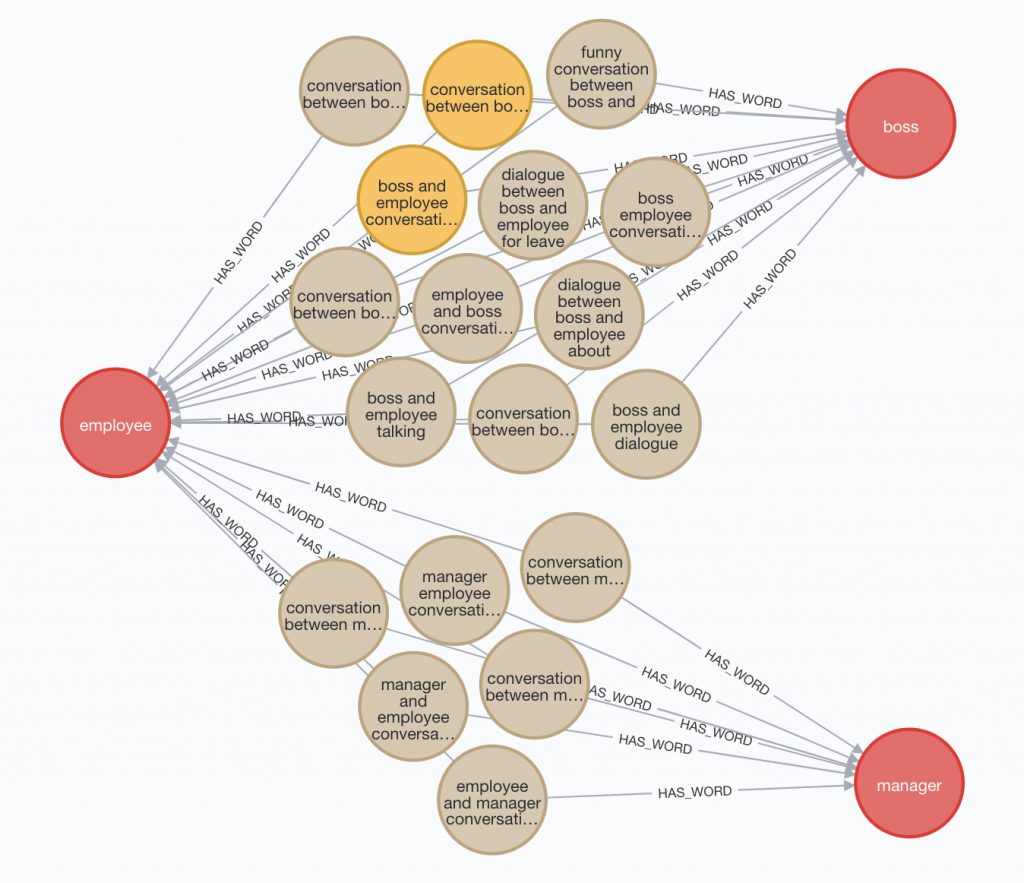
Interesting, right? Okay, yes this is still data we can get at with relational databases, at least when we’re filtering one or two words at a time.
So let’s flex on graphs.
How about: show me the best words I can layer onto any given article to improve existing rankings by finding connections between the words in Google keywords and the words on the page. That’d be a nightmare to do in a RDMS or spreadsheets.
Constructing a query that gets to a worthwhile answer
Show me the best words I can layer onto any given article by:
- measuring existing ranking opportunities as
- most impressions with threshold of low CTRs
- range like 5th to 20th average position rankings
- filter for words not being used on the page already
- sort by rankings with words with the most GSC impressions
Let’s start with impressions data.
MATCH p=(w1:Word)--(n:Term)--(w2:Word)
WHERE w1.name =~ "boss|manager" AND w2.name =~ "employee|worker"
OPTIONAL MATCH (n:Term)-[gsc:HAS_GSCAPI_DATA]-(u:URL)
WITH n, sum(gsc.impressions) as totalimpr, p, u.address as addy, n.name as term
RETURN totalimpr, addy, term ORDER BY totalimpr DESC
Okay that gives us total impressions for all our weeks of GSC impressions data, let’s aggregate it and check all URLs.
MATCH p=(w1:Word)--(n:Term)--(w2:Word)
// WHERE w1.name =~ "boss|manager" AND w2.name =~ "employee|worker"
OPTIONAL MATCH (n:Term)-[gsc:HAS_GSCAPI_DATA]-(u:URL)
WITH p, w1, n, w2, sum(gsc.impressions) as totalimpr, u.address as addy, n.name as term
WITH sum(totalimpr) as totalimpressions, addy, w1.name as names
RETURN totalimpressions, addy, names ORDER BY totalimpressions DESC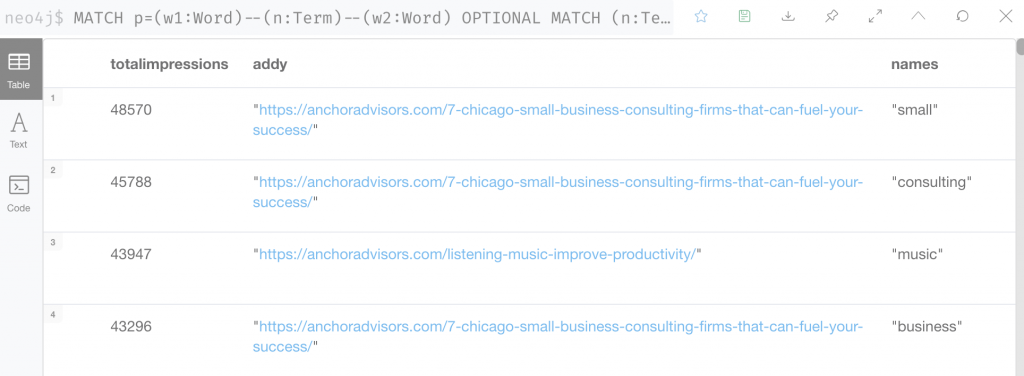
This is starting to get interesting. Of course, generic words have the most impressions. And it looks like most of these words are already in the URL, let’s exclude those and short words like “and”:
MATCH p=(w1:Word)--(n:Term)--(w2:Word)
OPTIONAL MATCH (n:Term)-[gsc:HAS_GSCAPI_DATA]-(u:URL)
WHERE NOT u.address CONTAINS w1.name
AND NOT size(w1.name) < 4
...Even after removing the most popular posts and missed stemmings, what we still get is synonyms. This isn’t bad, it actually makes me think there could be something here – potentially better wording to use for accessibility.
8442,boss,/a-conversation-between-an-employer-and-employee/
8260,dialogue,/a-conversation-between-an-employer-and-employee
6919,manager,/a-conversation-between-an-employer-and-employee/
5839,increase,/how-to-raise-prices-without-losing-clients/
5821,thanks,/5-small-gestures-gratitude-long
5627,turn,/why-candidates-decline-job-offers/
4460,reject,/why-candidates-decline-job-offers/
3853,same,/want-different-results-try-doing-something-new/
3754,small,/marketing-make-a-statement/
3576,what,/how-to-make-good-email-subject-lines/
3413,business,/partner-meeting-agenda/
But what if we excluded synonyms:
3753,politely,/how-to-communicate-with-your-boss/
3509,critical,/interview-questions-to-ask/
3345,important,/how-to-make-good-email-subject-lines/
3267,importance,/marketing-make-a-statement/
2518,letter,/how-to-raise-prices-without-losing-clients/
2511,professional,/billing-for-value-not-for-time/
2382,disc,/personality-tests-small-business/
2275,test,/interview-questions-to-ask/
1665,weighs,/interview-questions-to-ask/
A little better.
Exclude words already in the body of the articles
What if we also exclude words that are already in the body of our articles? Just to see what synonyms or words exist in keyword terms we are seeing impressions data on in Google?
MATCH p=(w1:Word)--(n:Term)
// WHERE w1.name =~ "boss|manager" AND w2.name =~ "employee|worker"
OPTIONAL MATCH (n:Term)-[gsc:HAS_GSCAPI_DATA]-(u:URL)
WHERE NOT toLower(u.content_text) CONTAINS w1.name
AND NOT size(w1.name) < 4
AND NOT u.address CONTAINS w1.name
WITH p, w1, n, sum(gsc.impressions) as totalimpr, u.address as addy, n.name as term
WITH sum(totalimpr) as totalimpressions, addy, w1.name as names
RETURN totalimpressions, names, addy ORDER BY totalimpressions DESC
Ok it still looks like our “top opportunities” are really just synonyms. And this is a very non-performant query that takes forever.
But there’s probably some value here – we should be using synonyms for accessibility and stronger signals. For example, clarifying that, yes, a post about employer-employee conversations applies to situations with “managers,” would probably give a small signal boost for manager related queries in Google on that article seeing a lot of impressions and not a lot of clicks.
Aggregate results by URL to show all missing words for articles still driving keyword impressions
Alas, we didn’t exactly find any clearly lush and ripe low hanging fruit. I wonder if we aggregated by url, collected all the terms and their GSC impressions sorted by the most, descending, would that give us a better idea of what we were missing?
MATCH p=(w1:Word)--(n:Term)
OPTIONAL MATCH (n:Term)-[gsc:HAS_GSCAPI_DATA]-(u:URL)
WHERE NOT u.address CONTAINS w1.name
AND NOT toLower(u.content_text) CONTAINS w1.name
AND NOT size(w1.name) < 4
WITH p, w1, n, sum(gsc.impressions) as totalimpr, u.address as addy, n.name as term
WITH sum(totalimpr) as totalimpressions, addy, w1.name as names
RETURN collect(totalimpressions) as imprz, collect(names), addy ORDER BY imprz DESCOh, beautiful!
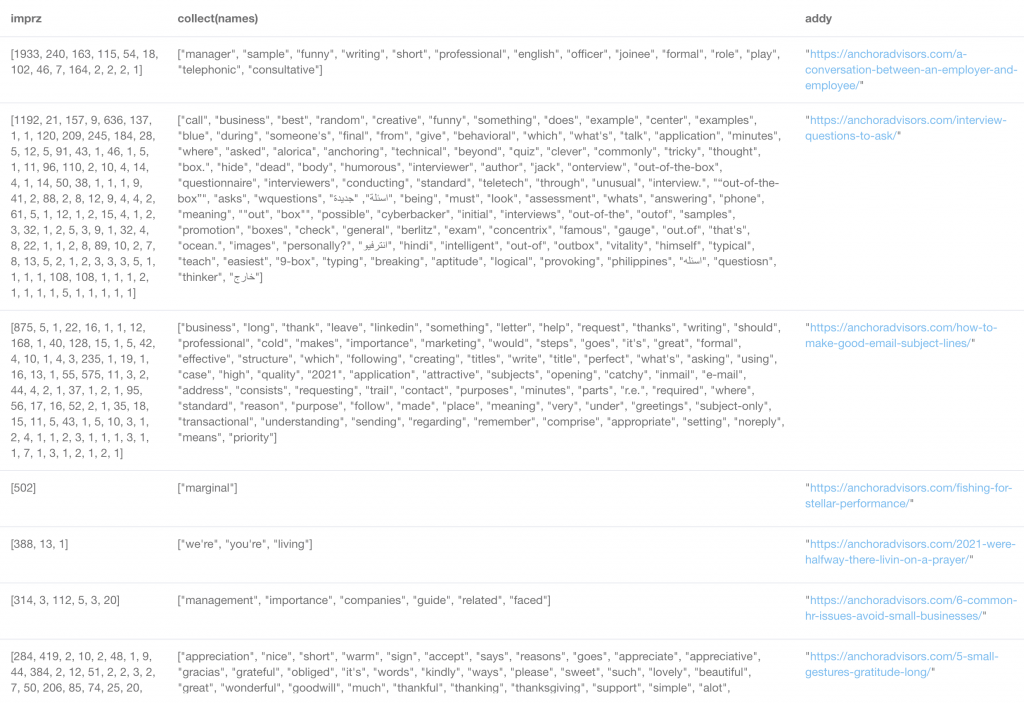
Let’s zoom in on one:

There’s a few thousand impressions here on a 20-30 words not being used on this post. I wonder what would happen if you passed this off to a copywriter / editor to update the top 10 posts with your highest impression word clouds not being used…
Yeah, they’d probably come back with lots of questions or start keyword stuffing.
Okay, let’s make this more actionable.
Show me the articles with the most impressions on Google Search Console terms that share a word that is also missing from that article’s body content or URL altogether.
Surely, it is worthwhile to know what exact words we are not using on the page that are still in phrases sending the most GSC impressions.
MATCH (n:Term)<-[gsc:HAS_GSCAPI_DATA]-(u:URL)
WITH n, n.name as phrase, collect(gsc.impressions) as collimpr, u, u.address as url
MATCH (w:Word)<-[hw:HAS_WORD]-(n)
WHERE NOT u.address CONTAINS w.name
AND NOT toLower(u.content_text) CONTAINS w.name
AND NOT size(w.name) < 4
WITH u, n, w.name as word, url, phrase, collect(phrase) as phrases, collimpr, REDUCE(acc1 = 0, v1 in collimpr | acc1 + v1) AS totalimprs
RETURN DISTINCT url, word, phrases, totalimprs ORDER BY totalimprs DESC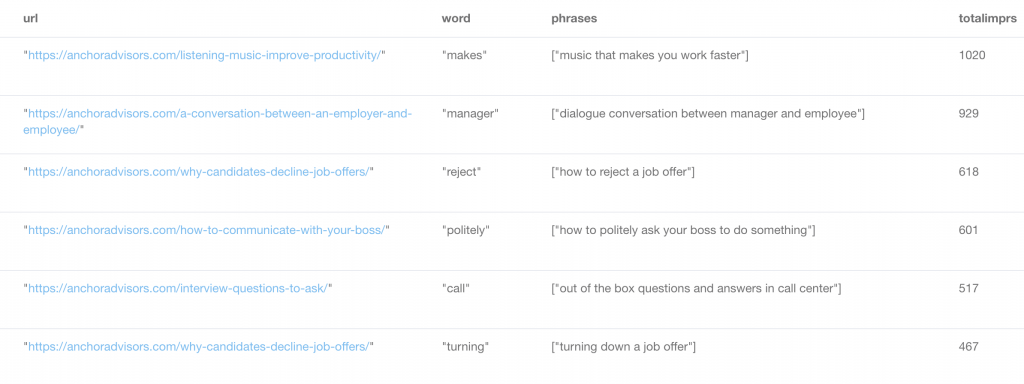
Voila! This is starting to look like a nifty headline improvements recommender. “Change ‘decline’ to ‘reject’ for an estimated extra 50 more visits per month”