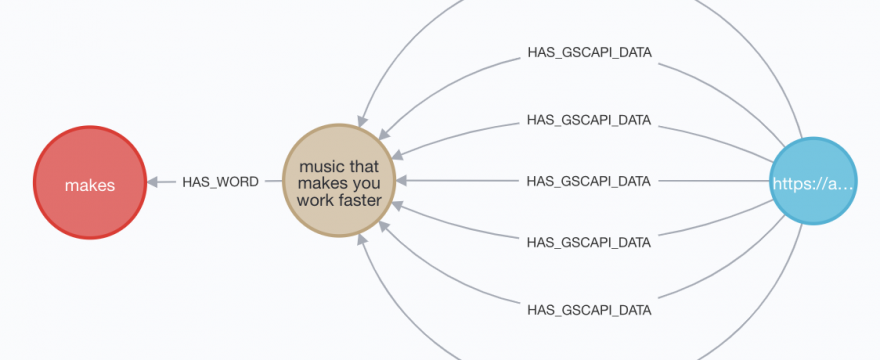
In order to query time series data, I felt like I had to model my google search console data this way in Neo4j: each day of data with clicks, impressions
In Google Search Console there are (for our purposes) three dimensions and four metrics:
- dimensions
- date
- url
- keyword
- metrics
- clicks
- impressions
- ctr
- avg. position
And so to get and be able to access the most accurate data in a time series, I had to store those four metrics on a daily basis for each URL to keyword combination. Like this:
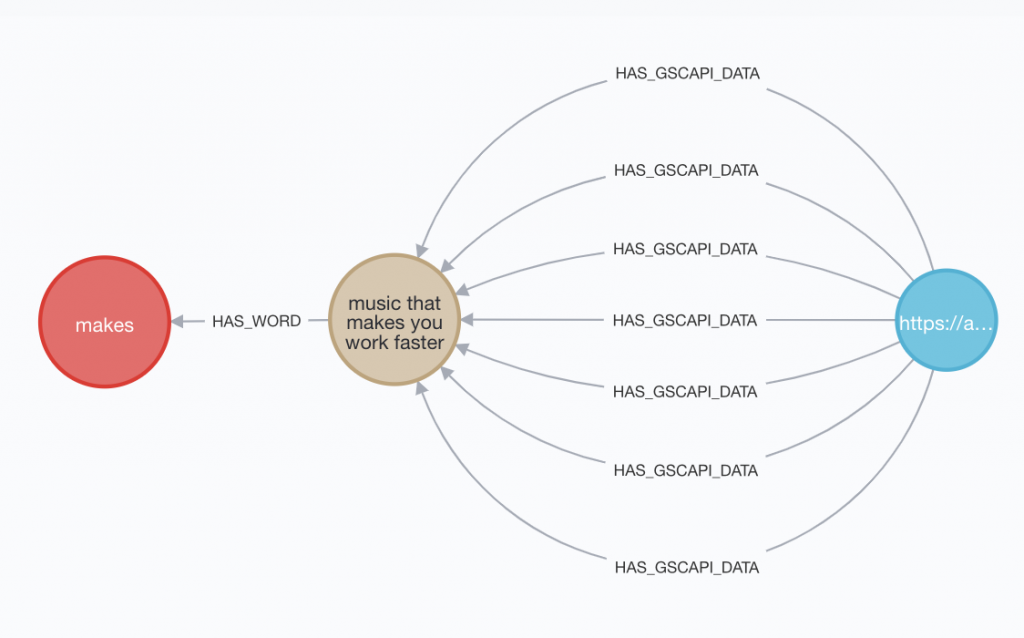
Right now the :HAS_GSCAPI_DATA relationship is an aggregate of one week’s data, but in the future it will be daily. The problem there is after a year, I’ll have potentially 365 relationships between a keyword and URL.
They say design your data model for the queries you want to be able to do. Basically, know what you want up front so you don’t get tangled up trying to get at it.
And so I need to work through, I’m sure for others, simple stuff to get to a performant query approach for summarizing lots of relationships property data between nodes.
MATCH (w:Word)<-[hw:HAS_WORD]-(n:Term)<-[gsc:HAS_GSCAPI_DATA]-(u:URL)
WHERE u.address = "/listening-music-improve-productivity/"
AND NOT u.address CONTAINS w.name
AND NOT toLower(u.content_text) CONTAINS w.name
AND n.name = "music that makes you work faster"This says give me paths between a specific URL and a GSC term and any words in that GSC term that are not on my URL. Here’s the second part:
WITH w.name as word, n.name as phrase, u.address as url, collect(gsc.impressions) as imprs
WITH imprs, word, url, phrase, REDUCE(acc1 = 0, v1 in imprs | acc1 + v1) AS totalimprs
RETURN word, url, phrase, sum(totalimprs)“WITH” lets you do lots of things, which I sort of learned the hard way but now re-reading the docs, I see that these are pretty clear.
The way I think about it, though, is by chaining WITH statements together, it lets me access and manipulate my data in a cascading way, filtering and ordering as I go without needing multiple queries that might otherwise force me to “write” new data as I go. I think of it as passing and altering variables – sort of like the openings for streams of data.
What WITH... collect(gsc.impressions) as imprs means is give me a combined list of the impressions for all the gsc relationships in a path between a URL and node.

The count of impressions for each of the 7 GSC relationships in the above model are now in that list. My next WITH clause “REDUCE”s that list so I can then tally up the impressions in the list to get an aggregate.
If I wasn’t getting ahead of myself I would have started with just aggregating the impressions for all GSC relationships like:
MATCH p=(n:Term)<-[gsc:HAS_GSCAPI_DATA]-(u:URL)
WITH p, n.name, u.address, REDUCE(totalImp = 0, r in relationships(p) | totalImp + r.impressions) AS totalimprs
RETURN url, phrase, sum(totalimprs)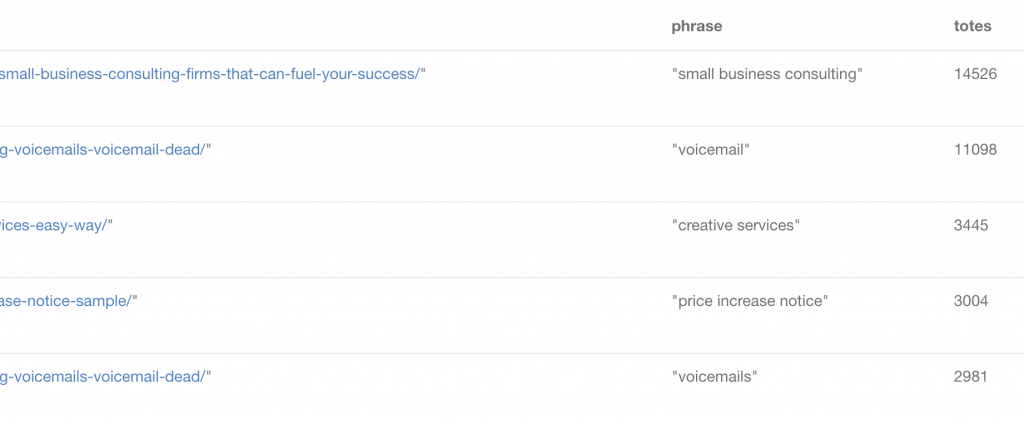
Which now makes me think I could WRITE this summary data, say monthly or quarterly for an analysis window I can quickly grab.
Here’s where I’d like to be, imagining a drop down:
- Today, Yesterday
- Last x days (7, 14, 28, 30)
- This x to date (week, month, quarter, year)
- Last x (week, month, quarter, year)
- Custom range
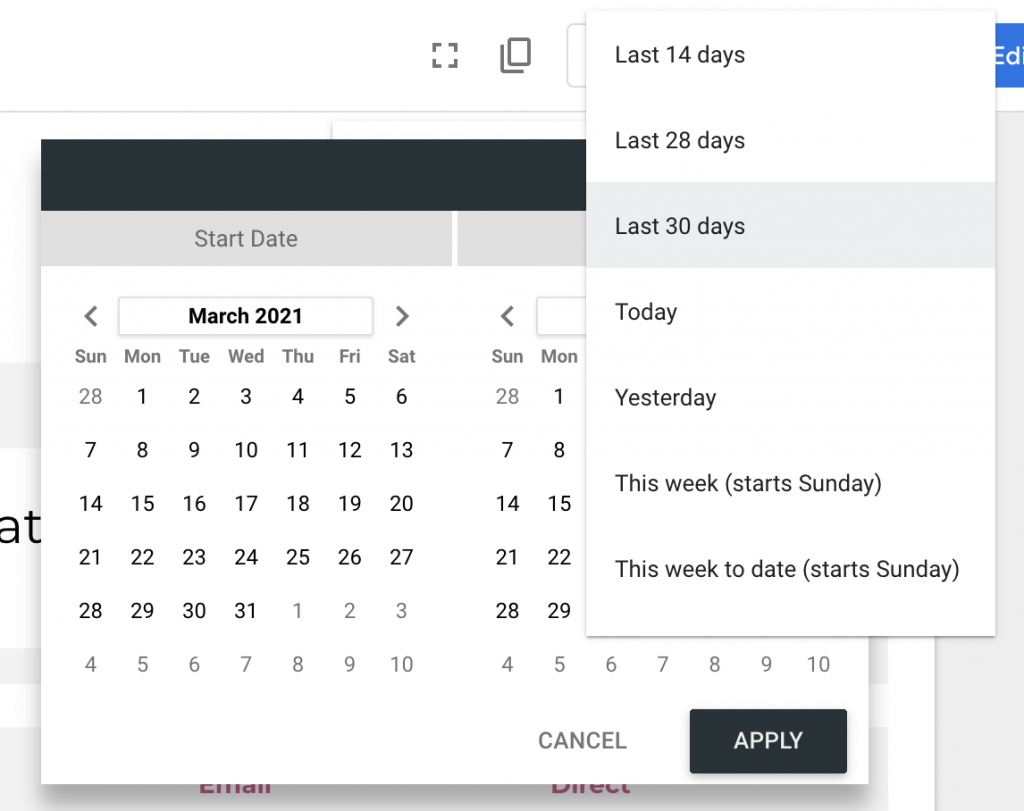
So let’s just start by grabbing the sum of our gspapi data’s impressions and writing a new relationship with the impressions’ total:
I’m starting with one path, and then I’ll build the query to loop through and “enrich” all paths with the totals:
MATCH p=(n:Term)<-[gsc:HAS_GSCAPI_DATA]-(u:URL)
WHERE u.address = "/listening-music-improve-productivity/"
AND n.name = "music that makes you work faster"
WITH p, n, gsc, u, n.name as phrase, u.address as url, REDUCE(totalImp = 0, r in relationships(p) | totalImp + r.impressions) AS totalimprs
WITH n, u, phrase, url, sum(totalimprs) as gsctotal
CREATE (n)<-[hg:GSC_TOTAL {impressions: gsctotal}]-(u)
RETURN hg.impressions
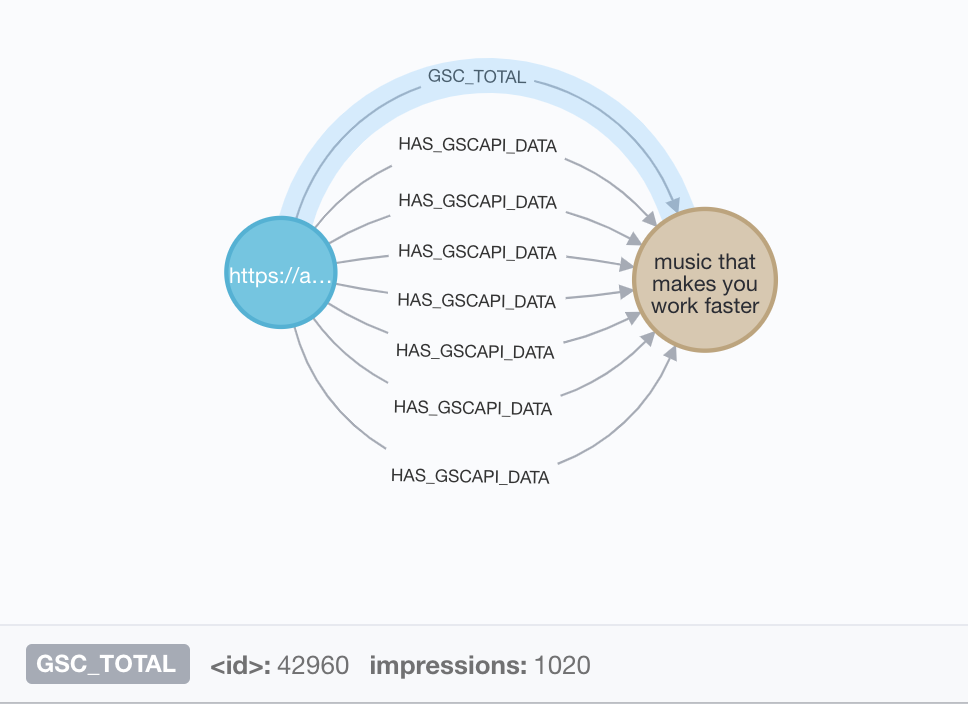
Aside: I forget that the WITH is so literal. We should only pass exactly what we want, I was passing everything and so I kept getting 7 GSC_TOTAL instead of 1 aggregated.
Let’s remove the WHERE clause so we can run through all the combos:
MATCH p=(n:Term)<-[gsc:HAS_GSCAPI_DATA]-(u:URL)
WITH p, n, gsc, u, n.name as phrase, u.address as url, REDUCE(totalImp = 0, r in relationships(p) | totalImp + r.impressions) AS totalimprs
WITH n, u, phrase, url, sum(totalimprs) as gsctotal
CREATE (n)<-[hg:GSC_TOTAL {impressions: gsctotal}]-(u)
RETURN url, phrase, hg.impressions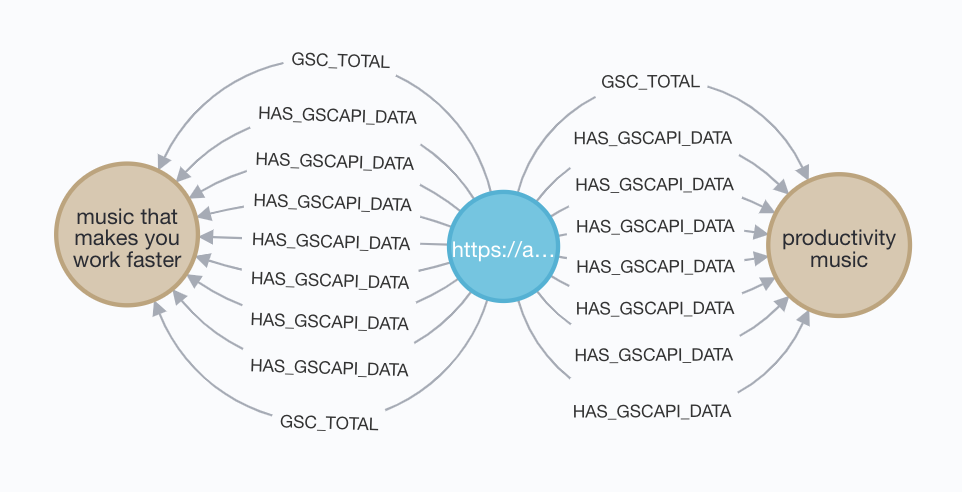
Success! As expected we have a summary relationship that matches our data, and our test node has two GSC_TOTAL’s as expected, one we’ll delete with MATCH ()-[r]-() WHERE id(r)=523293 DELETE r where the number is the relationship identifier.