This is a key early step in organizing expert content.
Keywords for our purposes just means one, two, three or so word terms that identify or are representative of an article or section of an article on your site.
Why extract keywords from your website articles?
When you go about organizing your site’s content, having a good list of keywords that represent what each document means can save you a world of time and surface insights you were unaware of, at least in aggregate.
You want extracted keywords that:
- can be extracted automatically or in aggregate, no one has time to do this by hand
- show you what pages discuss what topics at a glance, as well as what keywords commonly show up together in multiple articles (co-occurence)
- have some relevance or strength score on a per keyword to document basis (e.g. “SEO” is 0.9 for article A but only 0.2 for article B)
- show you at a high level how topics may relate, while allowing you to drill down into subcategories or terms associated with the high level topics
- are quickly filterable when all your URLs are in a spreadsheet (e.g. show me posts matching one of “seo|keyword research|semrush|google search console|gsc” with score over some relevance threshold like greater than 0.1)
- jog your memory, like in the case of a story, analogy, name, book (e.g. when I saw “couples therapy” as a term – I thought, “Oh right that’s when I compared content audits to couple’s therapy.”)
The tools and tricks I use for extracting useful terms from documents in a body of content fall into two general categories: search data and ML/NLP text analysis approaches.
Keyword extraction tools in a not so short list of approaches I have been using
Google Search Console – keywords by page even if no clicks and just impressions can paint an excellent picture – if this is what Google thinks your page is about, it is probably accurate (even if you don’t want to rank for “sleazy guys” when you’re post talks about facebook ad funnel bros). Cons here are you need the GSC API to extract keywords on a per page basis in aggregate – GSC > Performance section only allows you to see an aggregate of top terms or top pages, and while you can filter terms by a page, or filter pages by a term, it’s labor intensive when you have hundreds of pages.
Third-party ranking data – similar to GSC but often easier to get a list of keywords by URL and often more keywords, because it shows you a keyword a page is ranking for as long as it’s in the top 100 (up to 9th page of Google).
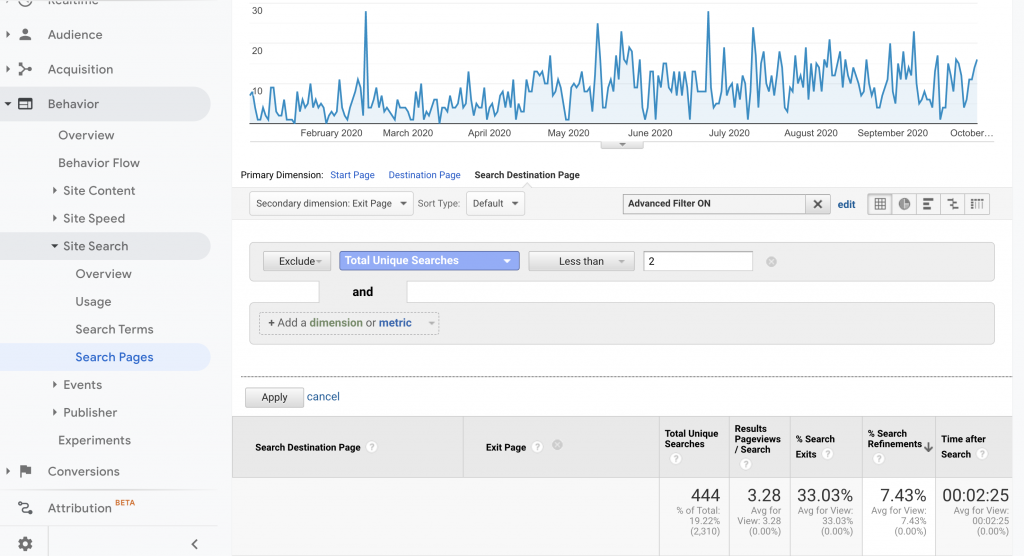
Site search data – if you have a lot of traffic, what do users type into your search bar, and then what results are shown, where do they click? This can surface practical terms being used in the wild (see Google Analytics > Behavior > Site Search > Search Pages with Secondary dimension Exit Page. Or have a dev hack at your server request logs with regular expressions to grab site search URLs from request and the following requested URL from the same IP).
TF-IDF (term frequency – inverse document frequency) is one of the simplest, and for organizing your own content, useful text analysis statistic/algorithms. Basically, your website’s pages become the corpus against which specific documents are judged on a per keyword basis.
The more rare a keyword is across your whole site, and the more it is used in fewer documents, the higher the score. If I have the term, “SEO” 10 times on one page, and then zero times on my other hundreds of pages, SEO for that page URL’s score will be quite high.
Experts who think by writing repeat themselves a lot. The benefit with TF-IDF is that it devalues any given page’s score for a term when you talk about on lots of pages. We are looking for terms uniquely relevant to pages when we extract keywords, so treating your website as the corpus against which each page is judged becomes a very useful method.
I write more about TF-IDF here – but this guide is in progress.
Gensim Textrank Summarization Keywords – Gensim is a free open source NLP/ML text analysis library for topic modeling purposes, known most for its extractive text summarization tooling.
The keyword summarization function looks for the most representative terms in a document by scoring terms similarly to how PageRank scores pages. BUT instead of counting links as votes, it counts words as votes.
If you understand how PageRank works, that hopefully makes sense.
For our purposes, it counts the value of pages based on the likelihood someone surfing webpages and clicking on links would find that page. If page A links to B and B links to page C, then the page A link is counted toward a scoring for page C, along with all the other links pointing to page to page to pages to that page. Here is a brief as possible 101.
For TextRank, the more words surround a given term and the more the words surrounding a term are surrounded by other words, the higher it’s score.
This TextRank illustration using a scientific abstract as the example really drove the concept home for me. First, the abstract:
Compatibility of systems of linear constraints over the set of natural numbers.
Criteria of compatibility of a system of linear Diophantine equations, strict inequations, and nonstrict inequations are considered. Upper bounds for components of a minimal set of solutions and algorithms of construction of minimal generating sets of solutions for all types of systems are given.
These criteria and the corresponding algorithms for constructing a minimal supporting set of solutions can be used in solving all the considered types systems and systems of mixed types.
https://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf
Humans, the control, selected the most important keywords as the follows, which I think looks pretty good:
linear constraints; linear diophantine equations; minimal generating sets; non−strict inequations; set of natural numbers; strict inequations; upper bounds
https://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf
Now the sexy part – the TextRank initial vectorization and graph mapping of adjectives and nouns and their collocations as nodes and relationships in a graph:
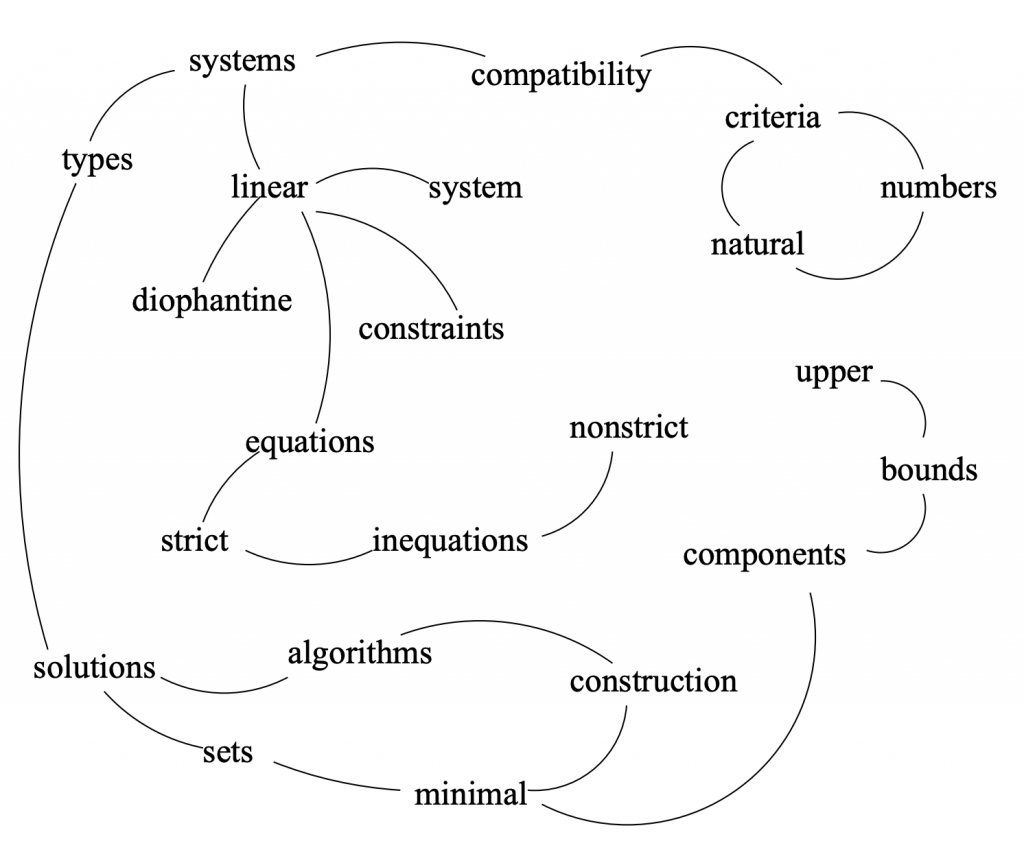
If you’ve followed any of my graph / network analysis emails, you’ll know that betweenness and centrality are indicators of influence.
Eyeballing it, we can see “linear” and “solutions” are central.
Aside/note to self, “systems” and “solutions” score high on betweenness. I’ve talked about betweenness algorithms, those bridge nodes that connect groupings of nodes as influential. I’d be curious how a betweenness algorithm scoring would do or in combination with PageRank based scoring.
Here is the output of TextRank:
linear constraints; linear diophantine equations; natural numbers; nonstrict inequations; strict inequations; upper bounds
It’s arguably better than the human annotated list of terms!
What I get out of the Gensim approach is that when context and relationships matters for understanding and analysis, which it always does, that leveraging graphs effectively is a superpower.
Next I’ll do some show and tell on how I’m using extracted keywords to analyze relationships between topics and existing pages. I’ve been working on this for about six weeks, excited to share progress and what I’ve learned!