I’m going to take a step back and walk through this graph-based content audit process step by step using a Philip Morgan’s site (with permission).
Philip writes daily emails to his email list and auto-publishes them to his website. A site crawl reveals 860 published articles.
This is a good use case for us to work through because he’s a subject matter expert with an audience who deals with a lot of abstract concepts. He writes books, sells info products, does consulting which makes mapping relevant content to respective calls to action or products in a cohesive way potentially useful. He also hasn’t done much content organization with the emails/articles or tried to “SEO” his posts.
It’s also a good use case because the original format of his posts was intended to be emails for thousands of people already familiar with his subject matter as opposed to stand alone articles.
This adds an interesting layer of complexity. A lot of the signals we might expect from a site full of articles (like on the nose headings or subheadings) aren’t really there because titles were meant to be email subject lines and article content was originally email body text.
This series seeks to explore the question, “what insights can we find that would improve the content performance on Philip’s site?
Onward!
Our first step is to wrangle our relevant site content into a graph database.
To do this we need to start with some pre-learning around the data to get a feel for what data we want, so we can do the simple data modeling necessary to map how we want things to get loaded in, and ultimately extract site content for Neo4j import.
1. Run and review site crawl data to get a feel for the site’s structure and size and determine what data and content is relevant
We start with a crawl of the site to get a feel for the file path structure, and isolate any URL patterns we might filter by to get a list of the URLs we want content from. I use a desktop SEO crawl tool called Screaming Frog (as an aside there is a free version that will allow you to crawl up to 500 URLs at a time).
Running a “Spider” mode crawl on philipmorganconsulting.com and export a few key reports to CSV:
- Internal (tab) > Filter: (dropdown) > HTML > Click “Export”
- Bulk Export (menu) > All Inlinks
- Bulk Export (menu) > Response Codes > Client Error (4xx) Inlinks
You can see the raw outputs as well as the tabs I’ve duplicated to work with in this Google Sheet.
Quick aside: This approach assumes no “orphaned” content, that is, content that happens to exist on the site but is not linked to within the site. Any orphaned pages would be missed in a traditional “spider” crawl.
An initial crawl returns 1,046 live html pages (with 200 status codes) and some good starter topic tags:
/tag/commoditization
/tag/daily-emails
/tag/decision+making
/tag/deep+expertise
/tag/experiential+learning
/tag/innovation
/tag/intellectual+property
/tag/lead+generation
/tag/mindset
/tag/PoV
/tag/product+positioning
/tag/research
/tag/risk
/tag/specialization
Looking that these raises some questions. A few are clearly home run topics, like lead generation. We all know what that is. Most people could benefit from consuming Philip’s content on lead generation.
For some of the more broad seeming topic tags, as a client and consumer of Philip’s content, I know he has very specific ideas in mind when he talks about these things.
For example, “research,” namely the type of research that independent experts can do to serve their target market in a way that helps one develop some authority and gravitas, might be more aptly described as “market research” or “practical research” or “customer research.” or something as “research” in other contexts means lots of things.
Same with PoV. Point of view in this context is an evolving concept being worked out by Philip and Bob Lalasz of Science+Story.
We’ll have to tuck this away and think about how (if) we want these tags to impact our NLP enrichment processes.
There are also some categories that hint at content formats, (events, daily emails, weekly emails) which we’ll ignore for now given they aren’t topic specific.
To get to a point where we can model the data, we have to make some decisions.
- Are we going to strip all HTML out or use meta data signals to “weight” importance of word/phrase meaning for a document (page)?
- Do we care to include headings or are they noise?
- What about links? Should we include any internal links between pages?
- How do we want to handle “tags”? Should the be properties we can filter by or their own “node” type with relationships to respective pages?
If we really don’t know, but also suspect some data could be useful to map, then we include it in a way where we have the option to ignore or target it later. If we suspect we won’t be using it, we can ignore for now and always add it in later.
There are no easy answers here, it’s case by case. Here’s my thinking on this one:
Include links within the emails/pages that reference other emails/pages, but exclude any templating links unrelated to email content
Based on the pre-learning, I can see any links would be skewed toward newer emails/pages referencing older pages and not vice versa (which is fine!)
Also, it looks like we have some broken links in a crawl (to be expected), so it’s possible URLs have changed over time without internal links also changing.
To isolate 404s coming from the pages we care about (luckily patterned as /indie-expert-list/), we first filter “Destination URL” column by “starting with” https://philipmorganconsulting.com/indie-experts-list/” to get only internal 404s and then also filter our “Source URL” column using a quick regex filter:
=AND(REGEXMATCH(B:B, “https://philipmorganconsulting.com/indie-experts-list/(.*)”), NOT(REGEXMATCH(B:B,”/tag/|/category/”)))
This filter says “show me URLs with the subdirectory ‘/indie-experts-list’/ AND NOT tag or category pages and let’s me spot check a few links to see if there is a pattern we can quickly account for. Running this filter and checking the number of unique matching cells is how we learn that we’re dealing with 860 emails.
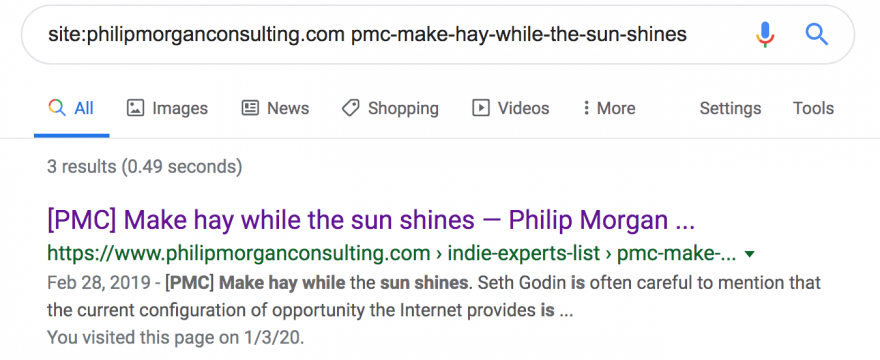
A corresponding “site:” search in Google for those pages shows the URL patterns have changed but the intended pages still exist and are indexed in Google.
site:philipmorganconsulting.com pmc-make-hay-while-the-sun-shines
What to search in Google to see if the intended page exists
Another quick aside: This won’t always work. If we didn’t find the pages this way, we could also use a site search feature, check for a site map, or look at other tools like Google Analytics that would show traffic data to similar URLs.
In our case we can see that the subdirectory of “/generate-leads-for-your-advisory-services/” was at some point changed to “/indie-experts-list/” for our first link. The page now lives at /indie-experts-list/pmc-make-hay-while-the-sun-shines.
We make a mental note this could be the case for the other links. Checking a few more, this looks to be the case.
Running a find/replace on the internal broken links in our Google Sheet tab “to find replace 404s for 200s” and then running them through Screaming Frog on “list” mode, shows that our new URLs all work. Now we have at least 100 links from within our articles that reference other articles where those relationships point to the intended pages.
Now that we have remapped our 404s to reference the correct pages, we have 100 relationships between posts we can potentially query later.
It also looks like we’ll want to exclude template based links between our pages.
Right now, each page links to the previous and next page in the footer:
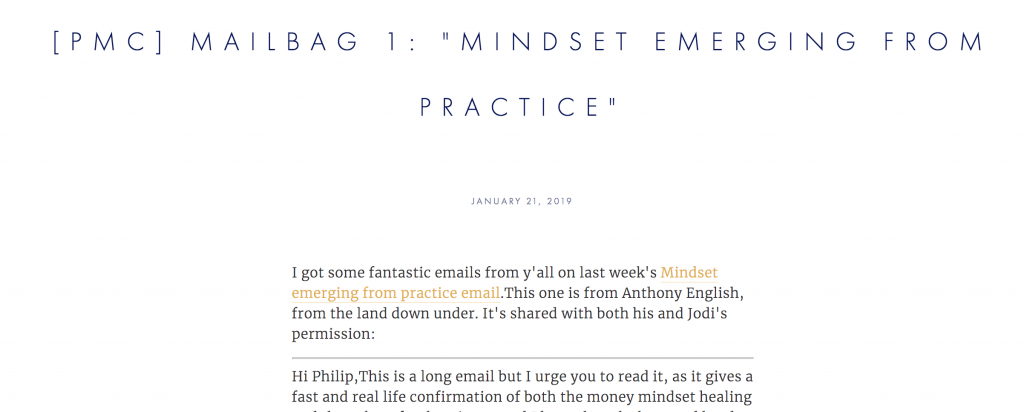
We don’t need or necessarily want to include these dynamically generated links outside of our articles as relationships the same way we want to map the intended links within emails/posts as referenced relationships between those emails/posts like this one:
That said, we do care about chronology. For that reason we can include these “next” and “previous” article links in the footers of each page as their own type of link relationship.
In addition we can number our posts from the first as 1 to the last as 1046 We’ll include dates when we map our content to the database, so w
Treating headings tentatively
For our headings and subheadings, we’ll do both: include them simply as text for our full text property analyses andnd also create additional properties for those page nodes with h tag information.
We have a good example in the above image. We can see a signal in the subject line/heading of “Mailbag,” which in Philip’s emails indicate something like the contents of the email are related to a reply to one of his previous emails.
Mailbags typically indicate a topic that’s getting high engagement or an email with a lot of replies worth parsing or at the very least, signal that not all the content on that page is written by Philip.
Good to keep in mind when we get to data enrichment phase. And a good reminder that what we’re doing needs to account for unique patterns related to the body of content at hand.
Respecting the taxonomies
Our tags are key topics or concepts and they’re the only real content organization we have. For that reason we want to treat them as a first class citizen in our database, so they get their own nodes with tagged as relationships like this:
( :Article ) – [ TAGGED_AS ] -> ( :Tag )
Even if it turns out that Philip hasn’t consistently used these tags, or they’re only used on newer emails, it still gives us a good starting point to identify what types of topics he cares about and that’s a big part of what we’re looking to surface at scale.
2. Scrape the site for the data we care most about
To summarize, the data we’ve decided to model and extract:
- page nodes with URLs as unique identifiers
- full text loaded in as a page node property including only non-templated contents of the page
- additionally, h tags (headings, subheadings) loaded in as page node properties, if multiple h2s, add as h2_1, h2_2, etc..
- date chronology refactored as numbered order properties to keep things simple, e.g. first found email/page is 1, then second is 2, etc., this way we at least have the option to query our database and consider post content and topics as they change over time
- link relationships between page nodes if this proves to not be too tricky
- include “broken” links that were meant to reference other emails/posts by cleaning those up as we enter that data to Neo4j so they reference intended posts
- exclude footer links to other posts but remember to have a way to consider and query content based on date or order
- topic tags as nodes and their link relationships with tagged articles
- luckily, our article source code links from all article pages to related tag pages and vice versa so this should be easy data to pull
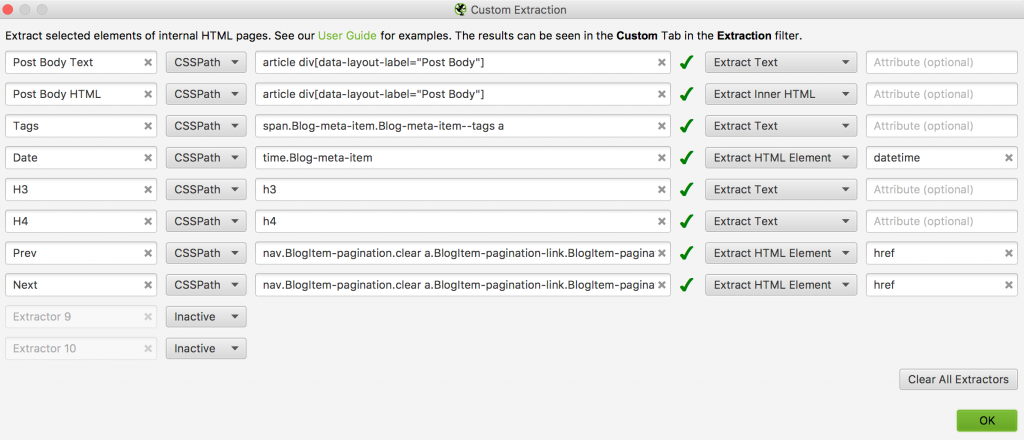
Screaming Frog offers a “Custom Extraction” method (found in Configuration (menu) > Custom > Extraction. It also has a configuration option to scrape “All Page Source” for each page which would give us all the source code for all pages if you preferred to refactor or cleanup in Neo4j or elsewhere.
Since we only want date, tags, title, headings, and body content from our 860 articles and the template Philip is using provides a way to target those with consistency, we can scrape just those data we want.
The short version here is to look for templating patterns by going to an article page and viewing source (you can do this with right click > “View Source” in Chrome.
In trying to identify what tags exist for a given post, I don’t see anything on the frontend. This is good! We don’t want to link to tag pages from all our article pages unless we want people to click through to them and search engines to rank them.
But, alas, once in the source code, a “Find” with Command (or CTRL) + F for “tag” shows the SquareSpace template outputs tag links for post tags in the source code in a targetable format.
Ideally we would either show those linked tags and try to rank those pages or remove them from the templating altogether, but that’s another story.
Given we have the tag data in the source like this:
<span class="Blog-meta-item Blog-meta-item--tags">
<a href="/indie-experts-list/tag/deep+expertise" class="Blog-meta-item-tag">deep expertise</a>,
<a href="/indie-experts-list/tag/innovation" class="Blog-meta-item-tag">innovation</a>,
<a href="/indie-experts-list/tag/research" class="Blog-meta-item-tag">research</a>
</span>We can add the CSSPath for this into Screaming Frog as:
span.Blog-meta-item.Blog-meta-item–tags a
We can further select “Extract Text” in Screaming Frog to just get the tag name. We do the same with the date stamp
<time class="Blog-meta-item Blog-meta-item--date" datetime="2019-07-10">July 10, 2019</time>In this case we simply call out our tag.class as “time.Blog-meta-item” and further select “Extract HTML Element” and then type “datetime” in the “Attribute (optional)” field. This allows us to only extract the “2019-07-10” from the targeted tag.
Screaming Frog will already pull URL, title, and Hx tag data by default, so now we just need to get body text content. Let’s see what an example output of the article text looks like:
Executing a simple research project of your own is SOOOOO EYE-OPENING1.
Okay so footnotes are added as numbers to the words, good to know.
…The LinkedIn sample Full resolution version of this file: pmc-dropshare.s3-us-west-1.amazonaws.com/Photo-2019-07-10-06-27.JPG The list sample (meaning people from this email list who responded to the same set of questions as the LinkedIn sample)…
Okay, some naked link as anchor text, good to know.
… And also, I’ll never be able to look at a news headline that says “New study shows $THING” without remembering the ability of abstraction to distort. -P
Okay sometimes variables are used, this is something technical people get that will definitely not make sense doing NLP things.
Here’s what’s been happening on my Daily Insights list: If you want to read up on this experiment, check out what might be one of my longest — and potentially most boring — series of emails: 1. philipmorganconsulting.com/pmc-survey-marketing/ 2. philipmorganconsulting.com/pmc-the-de-biasing-survey/ …
Okay, some footnotes and more naked text links. Maybe we just strip out the URLs that aren’t internally referencing other articles for now or not worry about it and see what happens.
[display-posts posts_per_page=”3″ include_excerpt=”true” category=”daily-insight”]
Okay, some shortcode data outputting, probably templating from a WordPress to Squarespace post export, we can strip that out.
But as preprocessing gets more involved, it probably makes sense to let some python libraries handle some of it. So we’ll also scrape the full HTML. Screaming Frog also doesn’t do H3 and H4 out of the box so we’ll add those as well. We get this config:
I’ll work on a better preprocessing workflow next.